
达观数据旨在为用户提供文本挖掘、智能推荐引擎、搜索引擎、微信抓取等方面的大数据技术服务,用户在使用达观服务后即可在数据大师平台看到各功能模块全面且详细的数据报告。本文以文本挖掘和微信抓取两大模块为例进行介绍,欲了解更多,欢迎注册数据大师账户或直接联系我们客服人员。
智能推荐引擎
智能推荐引擎旨在为用户提供使用推荐功能后的各项数据汇总,允许用户根据自己的需要来进行一些产品的禁止推荐和固定推荐。
推荐数据
推荐数据为用户展示了使用推荐功能后所带来的效果以及针对大众性、相关性和个体性推荐后的效果统计。
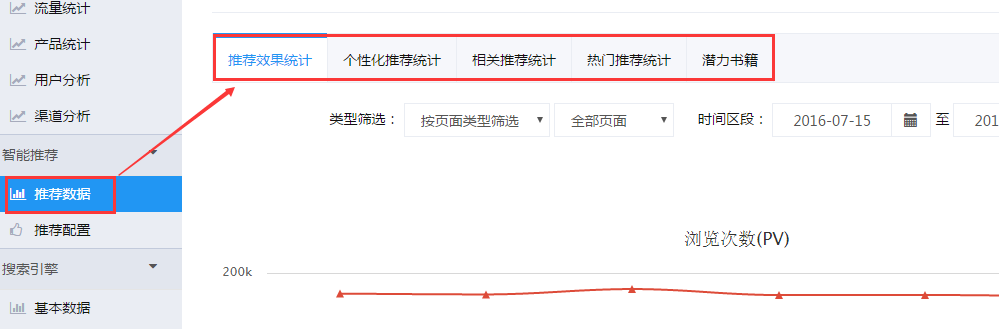
推荐效果统计
推荐效果统计展示了用户使用推荐功能后网站的浏览次数和访客情况。如下图2-3所示,用户可以直观看出在“按页面类型筛选”后的网站的浏览次数和独立访客数。

个性化推荐统计
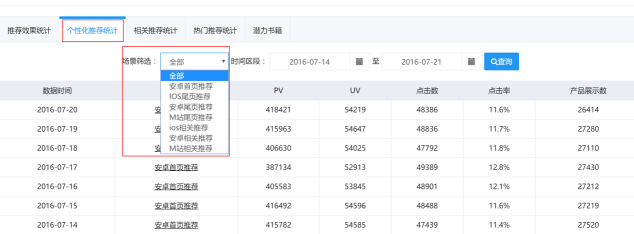
个性化推荐统计展示了针对每个访客的特性进行个性化推荐之后的数据,如下图2-4所示,用户可以直观看出在各个“场景筛选”条件下访客的访问次数和浏览次数。
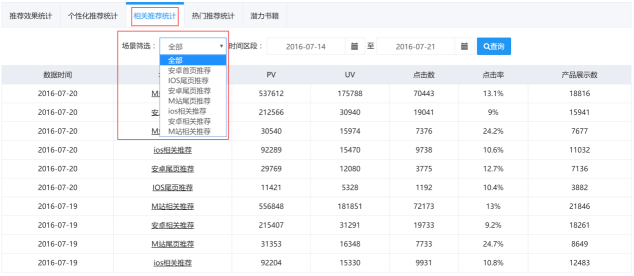
相关推荐统计
相关推荐统计为用户展示了针对网站各个访客的偏好进行推荐之后的数据,如下图2-5所示,用户可以通过点击“场景筛选”来查看在各个场景下的访客数、点击次数、点击数、点击率和产品展示数。
热门推荐统计
热门推荐统计是根据热点对用户进行推荐之后的数据统计。

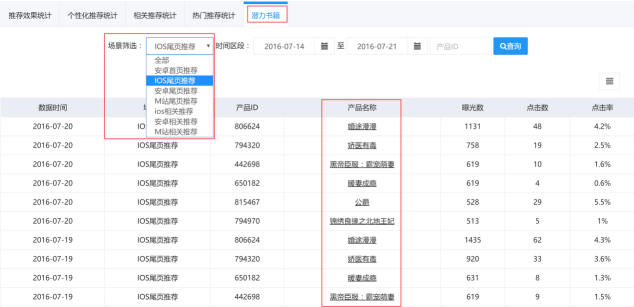
潜力书籍
潜力书籍是根据某小说网站的用户阅读情况进行的潜力书籍预测,并给出潜力书籍的曝光数、点击数和点击率,如下图2-6所示,2016年7月20号在ios尾页推荐上《婚途漫漫》的曝光数是1131,点击数是48,点击率是4.2%。
推荐配置
推荐配置功能可以让用户根据自己的需求来对一些产品进行禁止推荐设置和固定推荐设置。
推荐黑名单
用户可以通过推荐黑名单功能将一些产品放在黑名单来禁止这些产品被推荐在展示位上。
固定展示项
用户可以通过固定展示项来设置固定推荐的产品,以确保这些产品一定会被推荐在展示位上。
热门推荐
用户可以通过热门推荐功能来设置不同场景下的推荐参数及其权重。
搜索引擎
达观搜索引擎是一个“基于NLP技术和Logistic Regression、GBRT等机器学习算法,结合点击反馈模型的搜索排序,利用Hadoop、Spark、Kafka进行大规模分布式索引与算法模型的计算和分发,辅以自主研发的高性能消息传输组件DGIO(DataGrandIO)”的秒级分布式实时索引引擎。
优质的搜索引擎对网站的内容发现至关重要,但其搭建和运维的巨大成本却让人望而却步,搜索引擎成为了许多企业的业务瓶颈。
现在,达观以SaaS服务的形式将专业搜索技术简单化、低门槛化和低成本化,客户只需简单几步数据接入,即可使用专属的产品智能搜索功能。
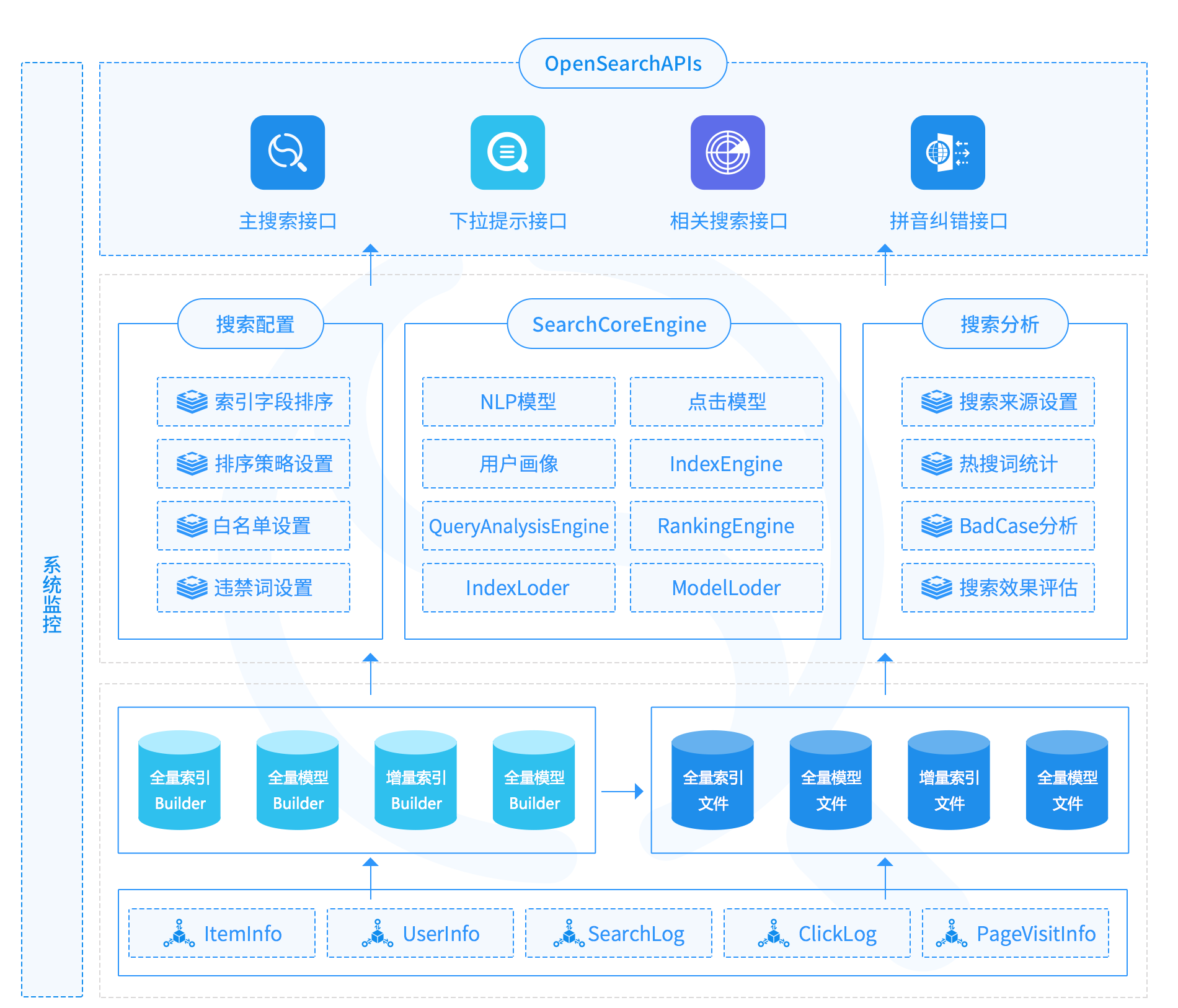
达观数据搜索引擎服务提供的功能包括:关键词搜索、搜索词提示、相关搜索词推荐、搜索词自动纠错和搜索词自动变换。能够有效识别用户搜索意图,解决结构化数据搜索需求,从海量数据中快速准确找到目标信息。在此基础上,达观还支持手动配置搜索结果,并对搜索效果数据进行统计。
功能介绍
关键词搜索
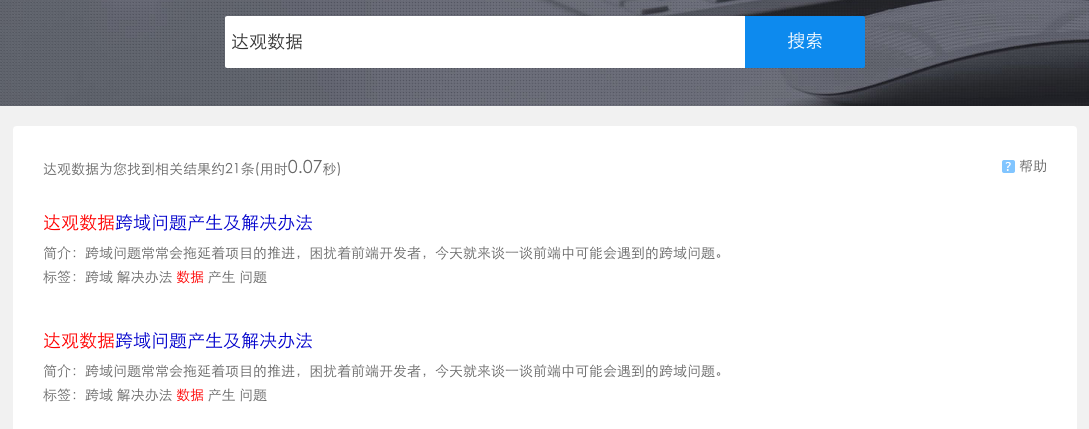
关键词搜索是最基本的搜索功能,用户输入关键词进行搜索,系统实时返回相关的结果。如输入“达观数据”,系统返回含有“达观数据”内容的搜索结果。达观搜索引擎可以在100毫秒内向用户返回搜索结果,并且支持对搜索结果进行筛选、自定义排序,帮助用户快速找到目标信息。
搜索词提示
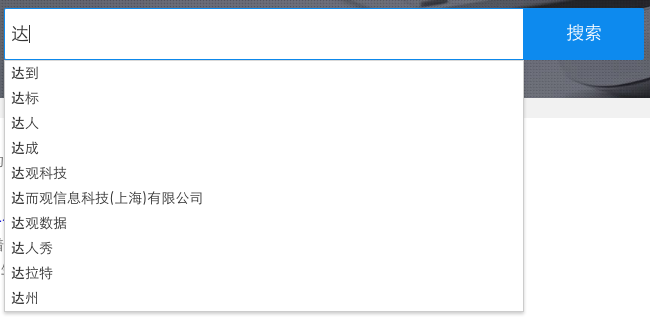
搜索词提示即系统根据用户当前已输入的部分关键词(如少量的字、拼音或声母等),识别用户搜索意图,自动提示完整的查询关键词。
如输入“达”,提示“达到”、“达标”、“达观数据”等。达观提供的搜索提示功能不只是简单地提示全网数据库中与已键入关键字相关的词条,而是根据搜索浏览点击等不同的用户行为提示用户可能搜索的词条。搜索词提示该功能可有效节省用户输入搜索词的时间成本、提升用户体验。
相关搜索词推荐
相关搜索词推荐即当用户输入一个搜索词时,系统推荐与当前搜索词相关的其他搜索词,帮助用户进行联想式查询。通过分析搜索引擎日志,可以挖掘出query的相关搜索词。
如当前搜索词为“达观”,相关搜索推荐“达观数据”、“达观科技”等。相关搜索词推荐功能可以引导用户发现其他更具体、更符合搜索需求的关键词,有效满足用户搜索需求,提升用户体验,延长用户在网站的停留时间。

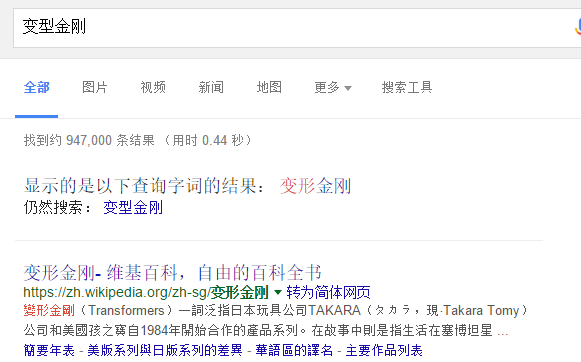
搜索词自动纠错即当用户出现英文单词拼写错误、中文乱用同音字、文字错输为拼音等输入错误时,系统自动识别并纠错,显示正确搜索词的搜索结果。拼写错误主要分为两种,一种是Non-word Error,指单词本身就是拼错的,比如将“happy”拼成“hbppy”,“hbppy”本身不是一个词。另外一种是Real-word Error,指单词虽拼写正确但是结合上下文语境确是错误的,比如“two eyes”写成“too eyes”,“too”在这里是明显错误的拼写。
中文搜索词以“变型金刚”为例,输入“变型金刚”,系统自动将搜索词改为“变形金刚”,并显示“变形金刚”的搜索结果。达观搜索词自动纠错功能支持英文拼写纠错、中文同音字纠错、拼音转换等,可以有效提升用户搜索结果准确度。
搜索词自动变换
搜索词自动变换即当用户输入的搜索词语义不明时,系统直接将其进行替换,显示替换后的搜索结果。直达搜索词表明用户非常直接的信息获取意图,对准确率要求高,召回率要求不高。如输入“今天天气”,系统自动把“今天”替换成当天日期,显示当天的天气预报。达观搜索词自动变换功能帮助用户准确获取其想要的搜索结果。
接入流程
达观以SaaS服务的形式将专业搜索技术简单化、低门槛化和低成本化,客户只需简单几步数据接入,即可使用专属的产品智能搜索功能。
第一步:开通账号,获取AppId和AppName
企业购买达观搜索引擎服务后,获得达观大数据平台专属账号和密码。登录后可以查看后台账号相关信息。
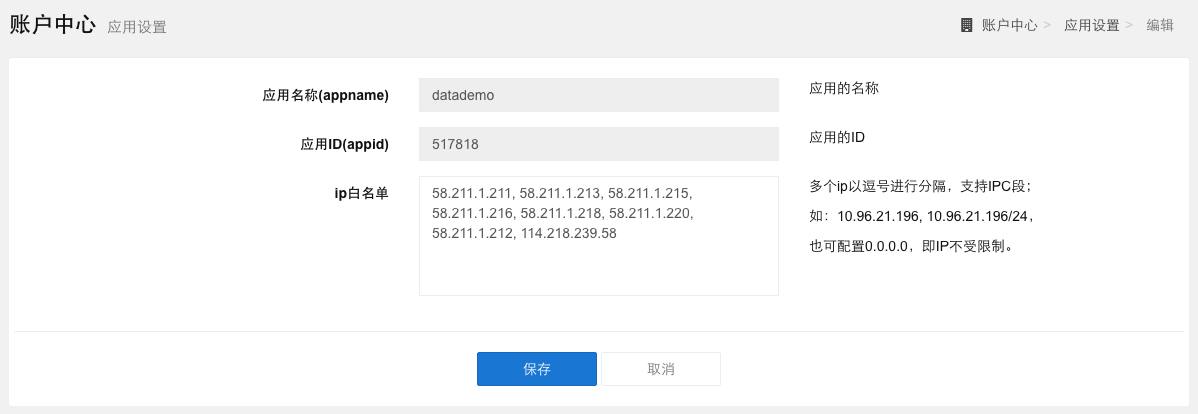
登录达观大数据平台后,在账户中心>应用设置中获取自己的应用信息。每位用户都有一个AppId和AppName作为唯一用户标识,也是后续调取搜索引擎服务API的必备参数。
为了安全起见,用户需要在应用设置中将自己的服务器IP加入白名单。达观系统只允许在IP白名单中的服务器进行调用,保证用户的服务和数据安全。
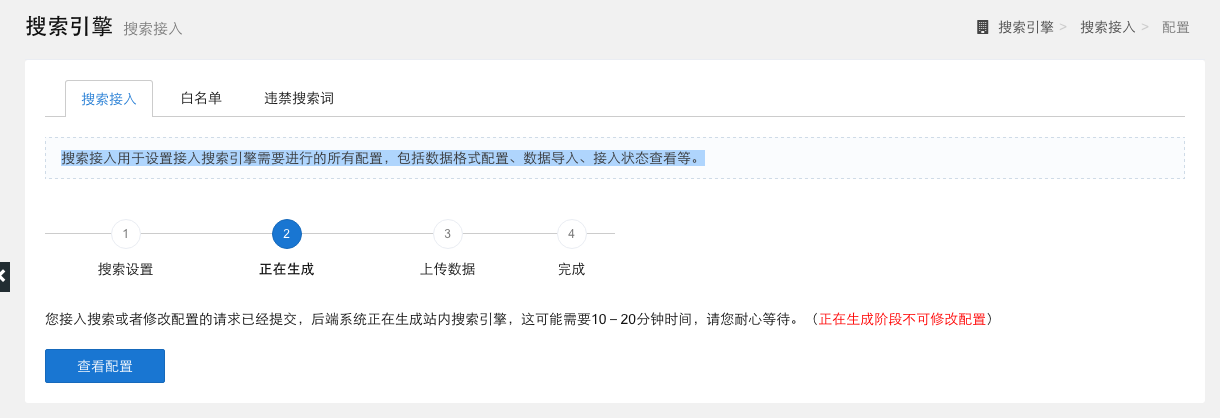
第二步:搜索接入配置
开通账号并获取应用信息后,用户需要根据自身需求,在达观大数据平台设置接入搜索引擎的所有配置,包括数据格式配置、数据导入、接入状态查看等。
第三步:上报数据
完成搜索接入配置后,用户需要上报数据,上报数据是接入达观大数据服务的基础。
数据可通过HTTP或者SDK两种方式上传,其中HTTP方式(主要方式)适合用于进行单条的、增量的方式上传,或者单条数据的修改、删除等操作,使用者也可以将批量数据,拆分为单条后使用HTTP方式来发送;SDK适合进行大批量的数据的上传。
数据上报文档http://doc.datagrand.com/developer/data-report
第四步:接口调用
完成数据上报后,即可开始调用达观数据搜索引擎接口,接口包括关键词搜索服务、自动补全服务、相关搜索服务请求和热门搜索词接口。
搜索配置
用户可以在达观大数据平台中进行搜索配置, 登录达观大数据平台,点击搜索引擎菜单下的“搜索配置”,进入搜索配置功能。
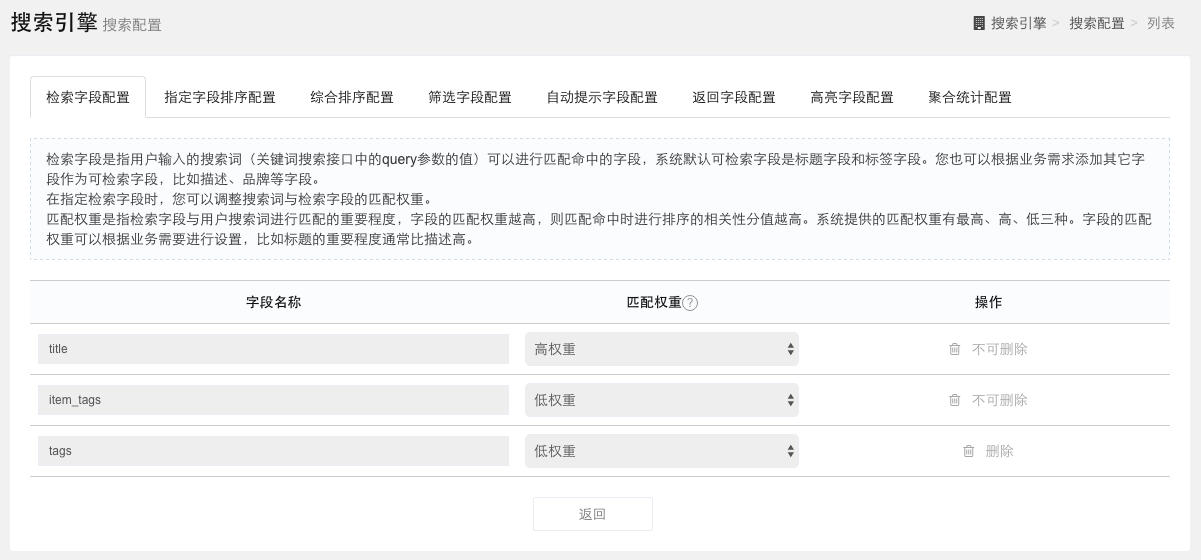
检索字段配置
检索字段是指用户输入的搜索词(关键词搜索接口中的query参数的值)可以进行匹配命中的字段,系统默认可检索字段是标题字段和标签字段。您也可以根据业务需求添加其它字段作为可检索字段,比如描述、品牌等字段。在指定检索字段时,您可以调整搜索词与检索字段的匹配权重。匹配权重是指检索字段与用户搜索词进行匹配的重要程度,字段的匹配权重越高,则匹配命中时进行排序的相关性分值越高。系统提供的匹配权重有最高、高、低三种。字段的匹配权重可以根据业务需要进行设置,比如标题的重要程度通常比描述高。
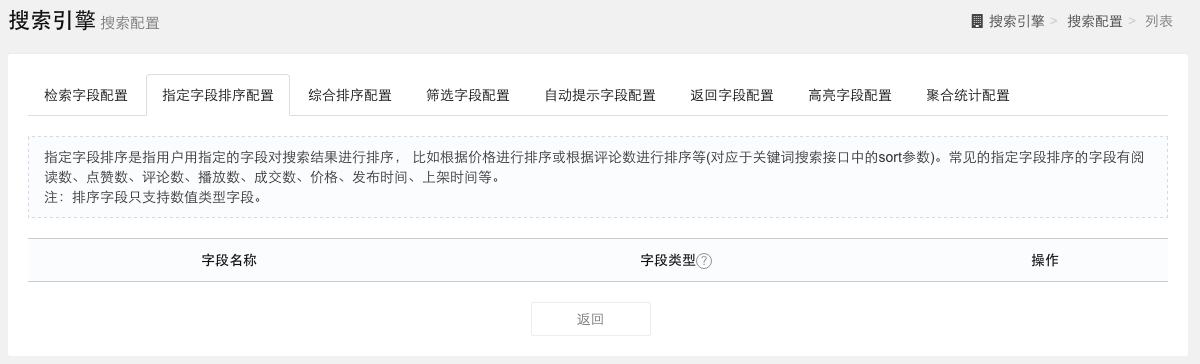
指定字段排序配置
指定字段排序是指用户用指定的字段对搜索结果进行排序, 比如根据价格进行排序或根据评论数进行排序等(对应于关键词搜索接口中的sort参数)。常见的指定字段排序的字段有阅读数、点赞数、评论数、播放数、成交数、价格、发布时间、上架时间等。
注:排序字段只支持数值类型字段。
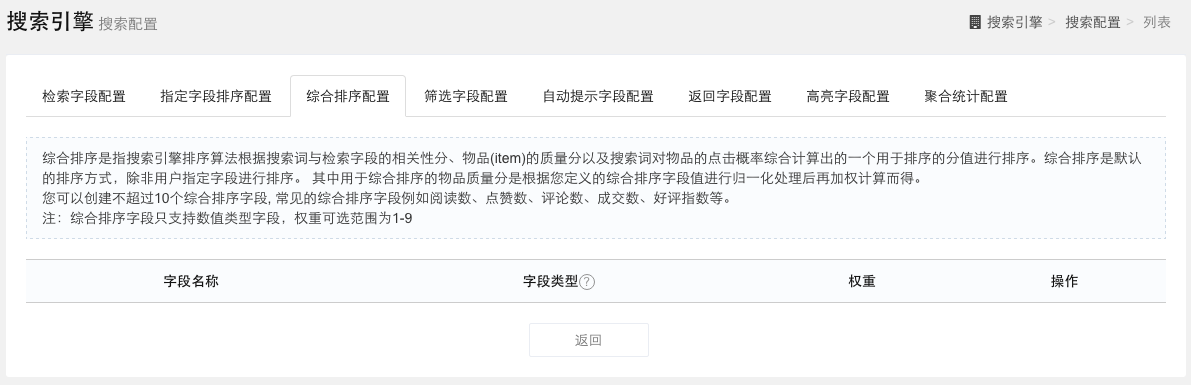
综合排序配置
综合排序是指搜索引擎排序算法根据搜索词与检索字段的相关性分、物品(item)的质量分以及搜索词对物品的点击概率综合计算出的一个用于排序的分值进行排序。综合排序是默认的排序方式,除非用户指定字段进行排序。
其中用于综合排序的物品质量分是根据您定义的综合排序字段值进行归一化处理后再加权计算而得。
用户可以创建不超过10个综合排序字段, 常见的综合排序字段例如阅读数、点赞数、评论数、成交数、好评指数等。 注:综合排序字段只支持数值类型字段,权重可选范围为1-9
筛选字段配置
搜索引擎支持用户对召回结果可以进行更进一步的筛选,比如根据价格区间进行筛选、根据发布时间进行筛选。筛选字段支持多值(分号隔开,如”北京;上海;深圳”)。常见的筛选字段有阅读数、点赞数、评论数、播放数、成交数、价格、发布时间、上架时间、品牌、产地、类目、状态等。
用户在这里设置可以进行搜索结果筛选的字段(对应关键词搜索接口中的filter参数或range参数)
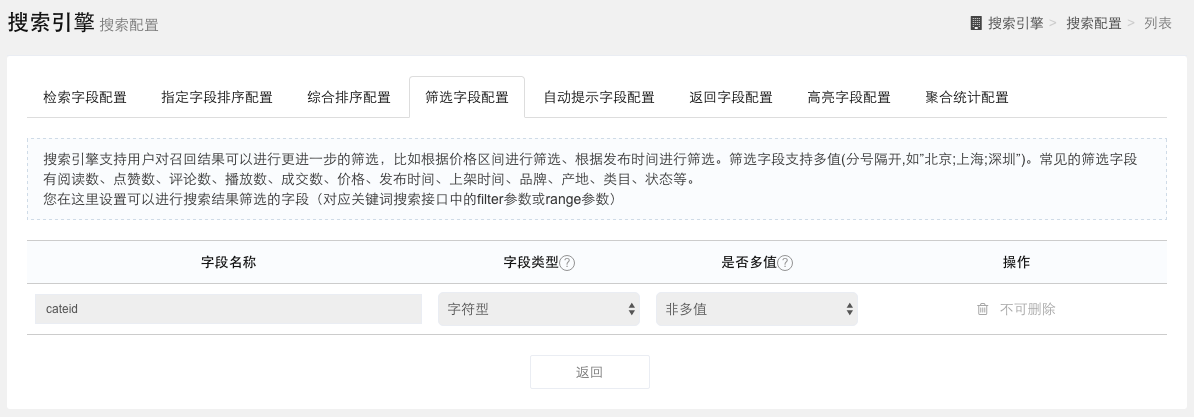
自动提示字段配置
自动提示(又称autosuggest)是指用户在搜索框输入部分搜索词时搜索引擎自动提示与此相关的完整的搜索词列表,用户可点列表中的搜索词直接进行搜索。自动提示候选词主要来自用户的搜索日志,您也可以设置相关字段作为自动提示的候选词,比如物品的标签、品牌等字段。
注意自动提示字段只支持字符型字段。
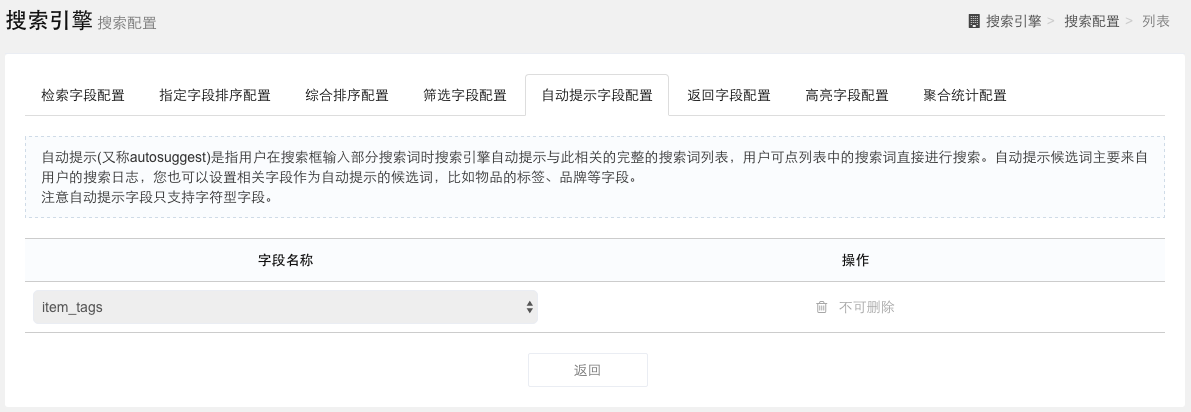
返回字段配置
达观搜索默认返回匹配到的物品ID(itemid)字段,您也可以在关键词搜索接口中的fields参数指定返回所有已经设置的匹配字段,排序字段以及筛选字段。除此之外,您还可以在此设置其他需要搜索引擎能够返回的字段。
注:返回字段需要在已经上报的字段中。
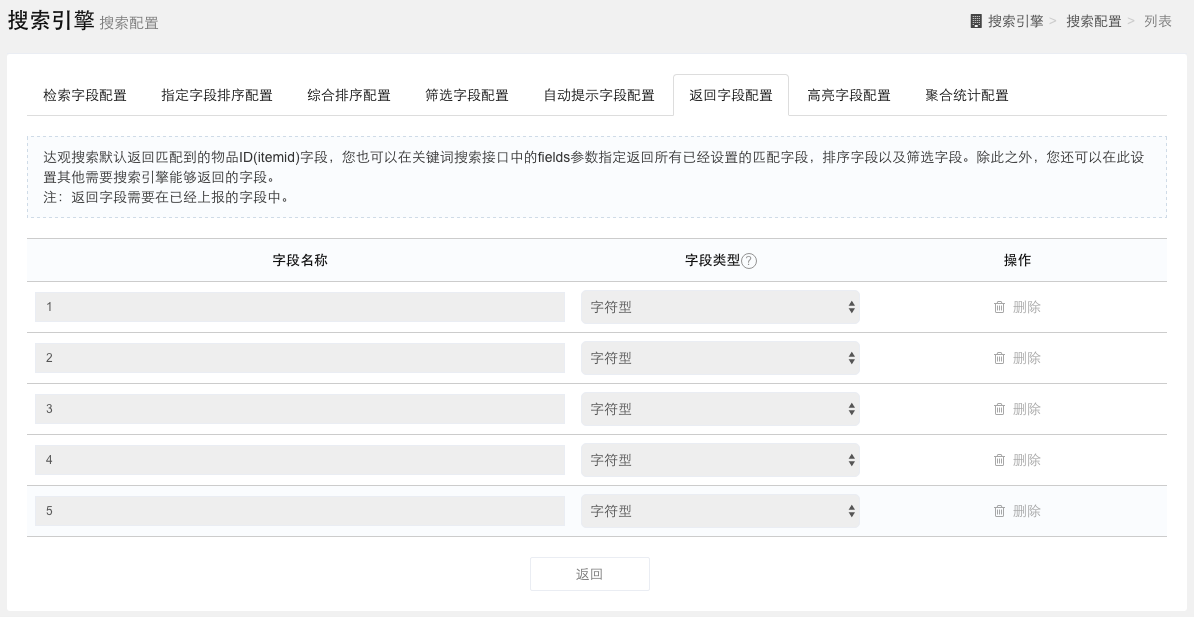
高亮字段配置
高亮字段是指搜索结果返回的用于显示高亮命中的搜索词所在的字段,比如标题字段或描述字段。注意高亮字段只支持字符型字段。
聚合统计配置
聚合统计是指对搜索结果按指定属性字段进行数目统计, 便于用户对搜索结果进行属性筛选。您可以在此设置属性字段(比如品牌、产地、类目等)进行聚合统计。支持对数值型和非多值的字符型字段进行聚合统计。
API调用
搜索引擎接口文档http://doc.datagrand.com/developer/search-engine
数据统计
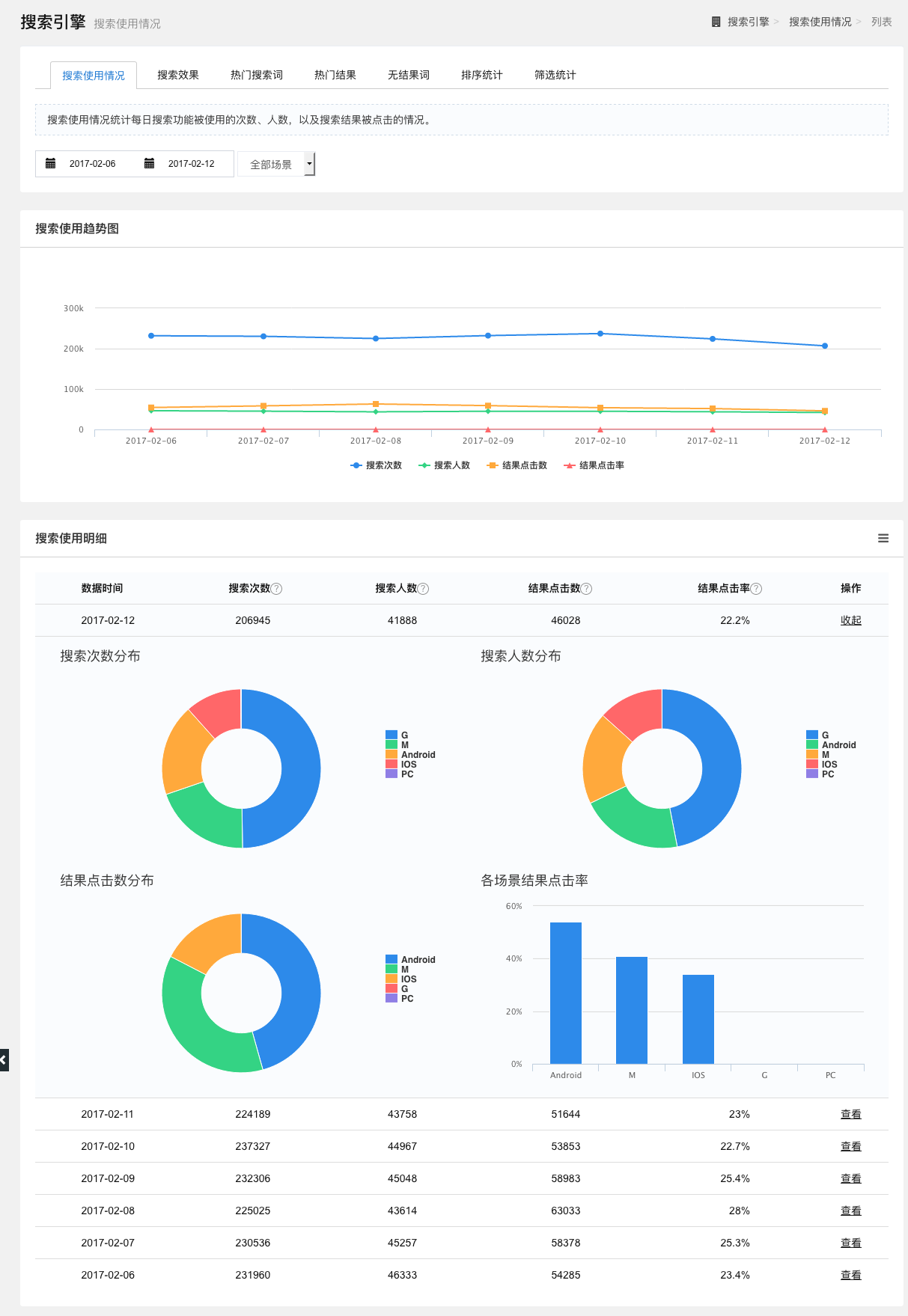
搜索使用情况
统计每天使用搜索功能的人数(UV),搜索功能被使用的次数(PV),搜索结果被点击的次数,以及结果点击率。用户可以通过筛选条件——时间区段和场景(如IOS、PC或者安卓等);点击折线图下方的图例,可以选择展示的数据;在折线图下方,以列表形式展示一段时间内,每天的搜索次数、搜索人数、搜索点击数和结果点击率;点击数据列表中的“查看”,可查看当天的搜索数据来源分布。
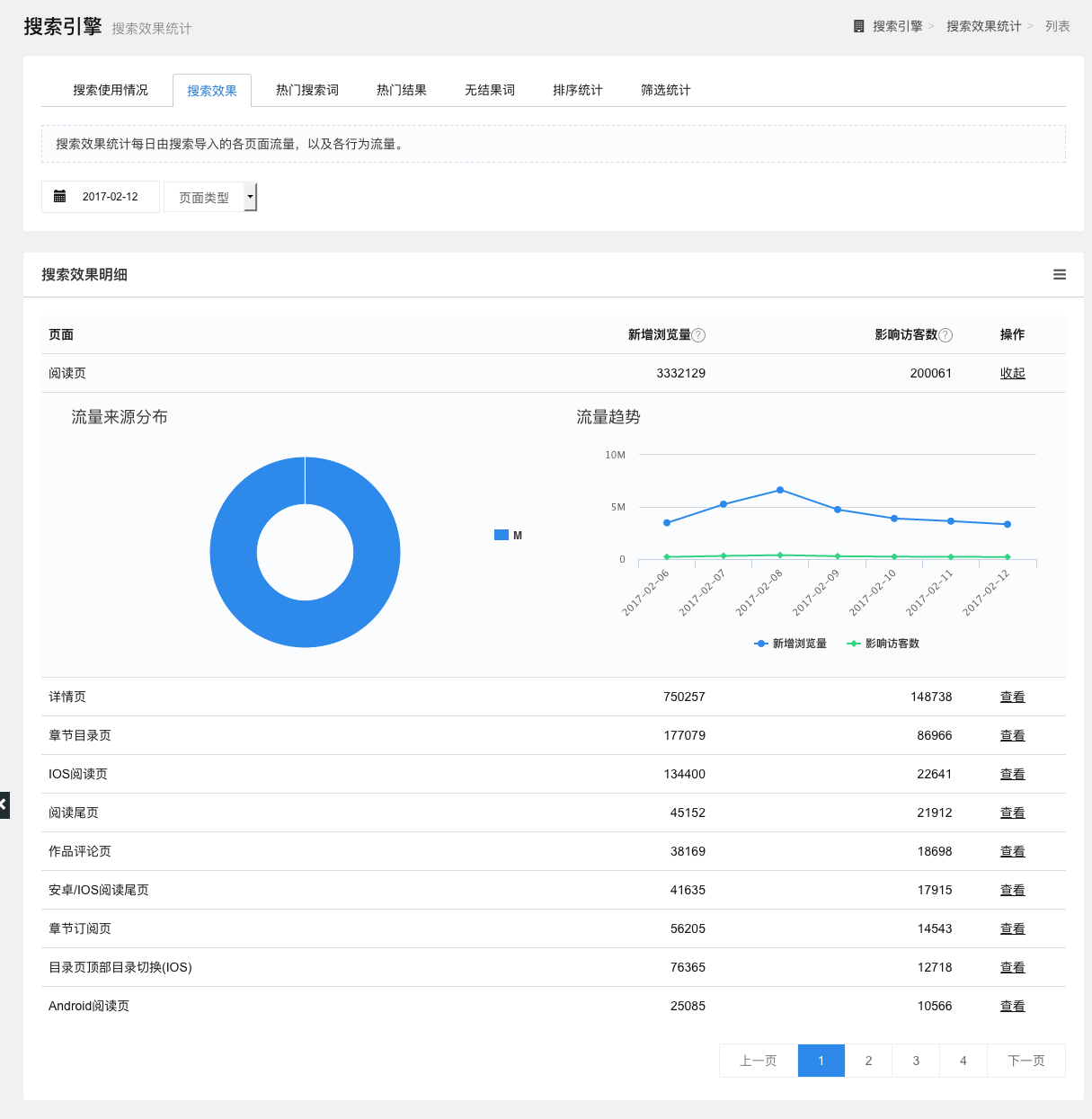
搜索效果
统计每日由搜索导入的各页面流量,以及各行为流量。
用户可以通过筛选日期和效果明细(页面/操作)来查看数据,根据筛选条件,以列表形式展示页面(操作)、新增浏览量和影响访客数,点击“查看”按钮,可查看对应页面(操作)的流量来源饼状图和流量趋势(新增浏览量和影响访客数)折线图。
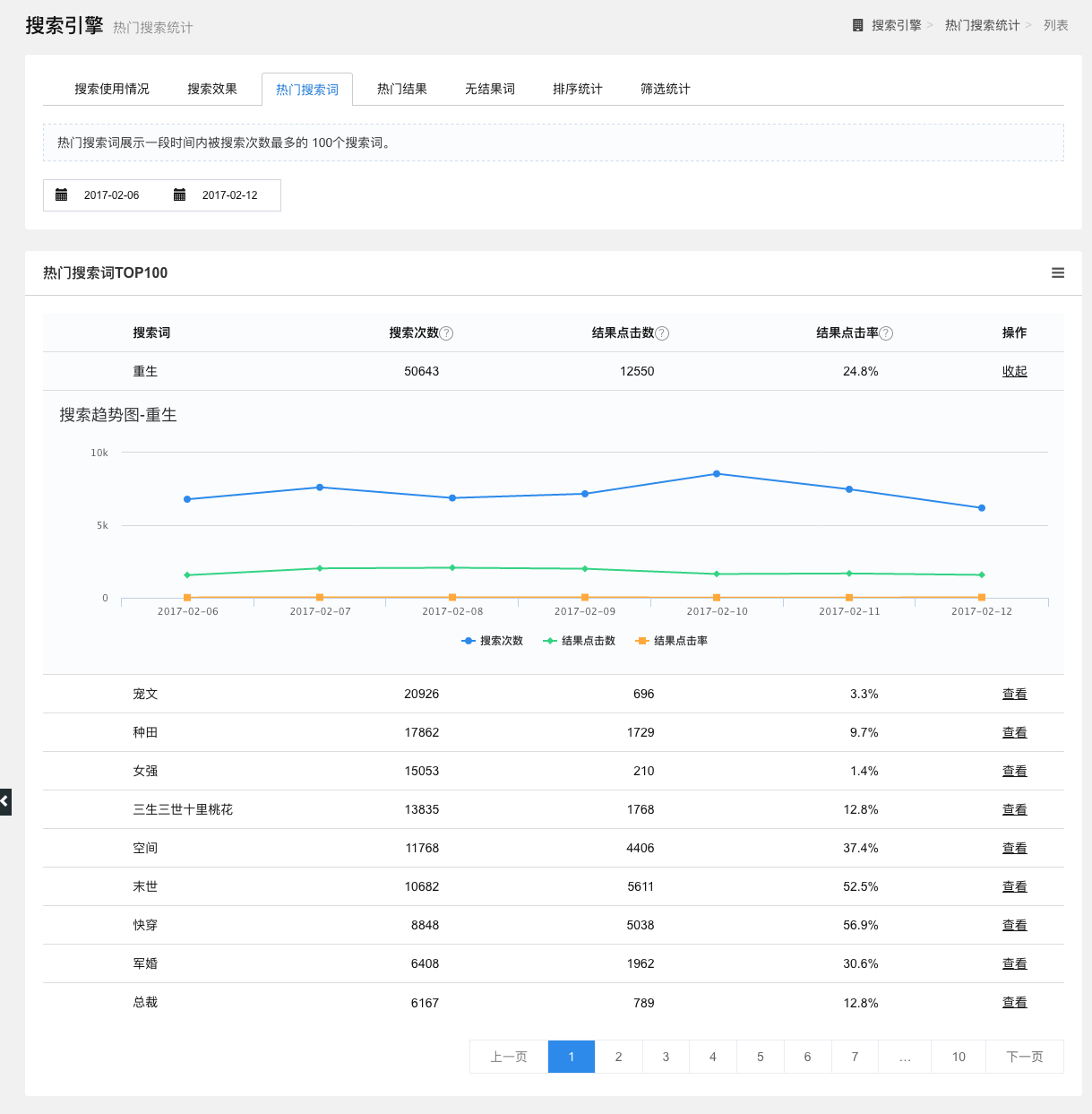
热门搜索词
展示一段时间内被搜索次数最多的100个搜索词。可通过选择时间区段筛选数据,以列表形式,展示该时间区段内最热门的搜索词、搜索次数、结果点击数和结果点击率。
点击操作一栏中的查看按钮,可查看该搜索词的搜索趋势图(搜索次数、搜索点击数、搜索点击率折线图),点击折线图下方的图例,可选择查看的数据。
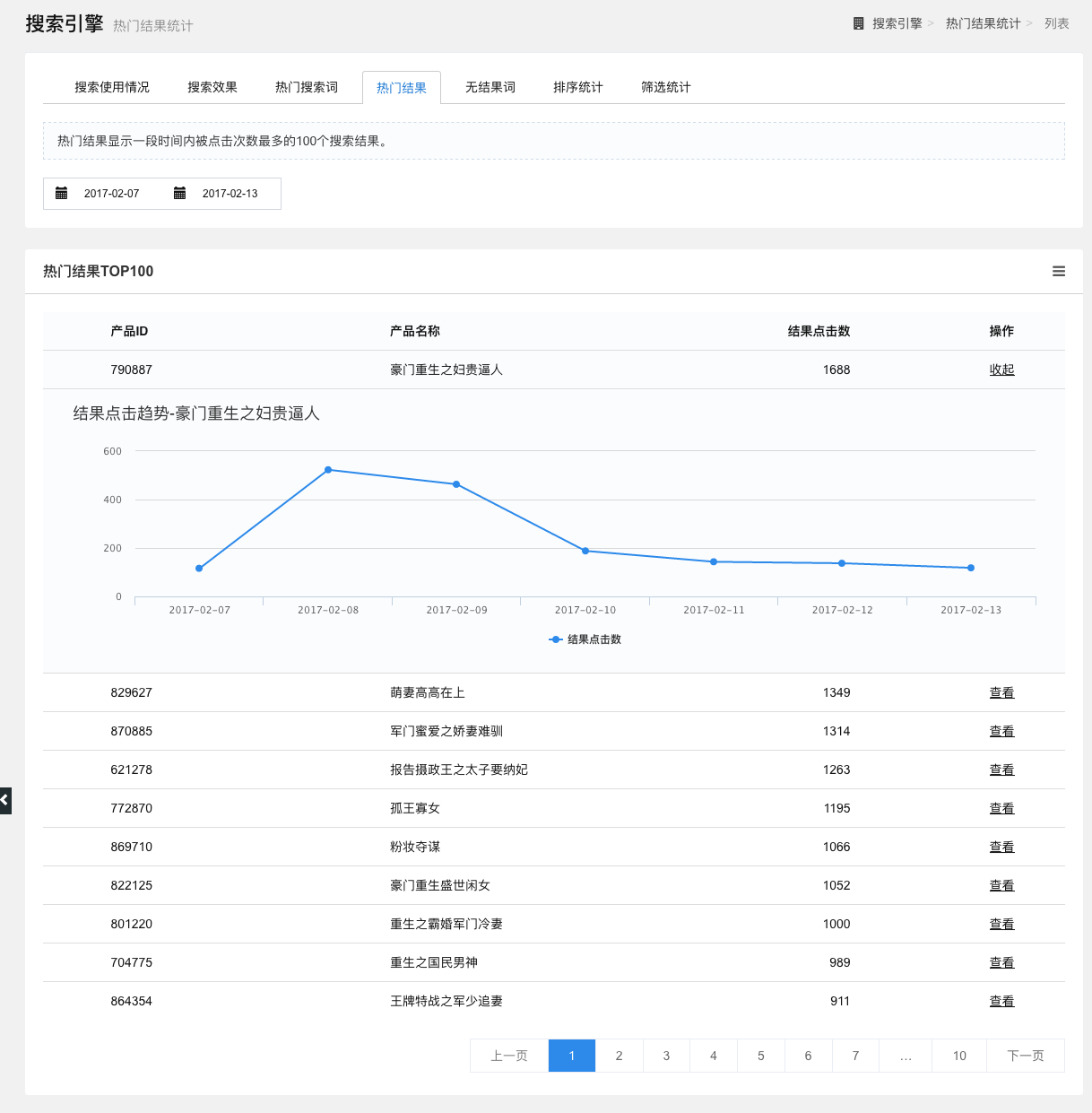
热门结果统计
统计一段时间内被点击次数最多的100个搜索结果。
通过选择时间区段筛选数据,以列表形式,展示该时间区段内最热门结果产品ID、产品名称和结果点击数。点击操作一栏中的查看按钮,可查看该搜索词的搜索趋势图(搜索点击数折线图),点击折线图下方的图例,可选择查看的数据。
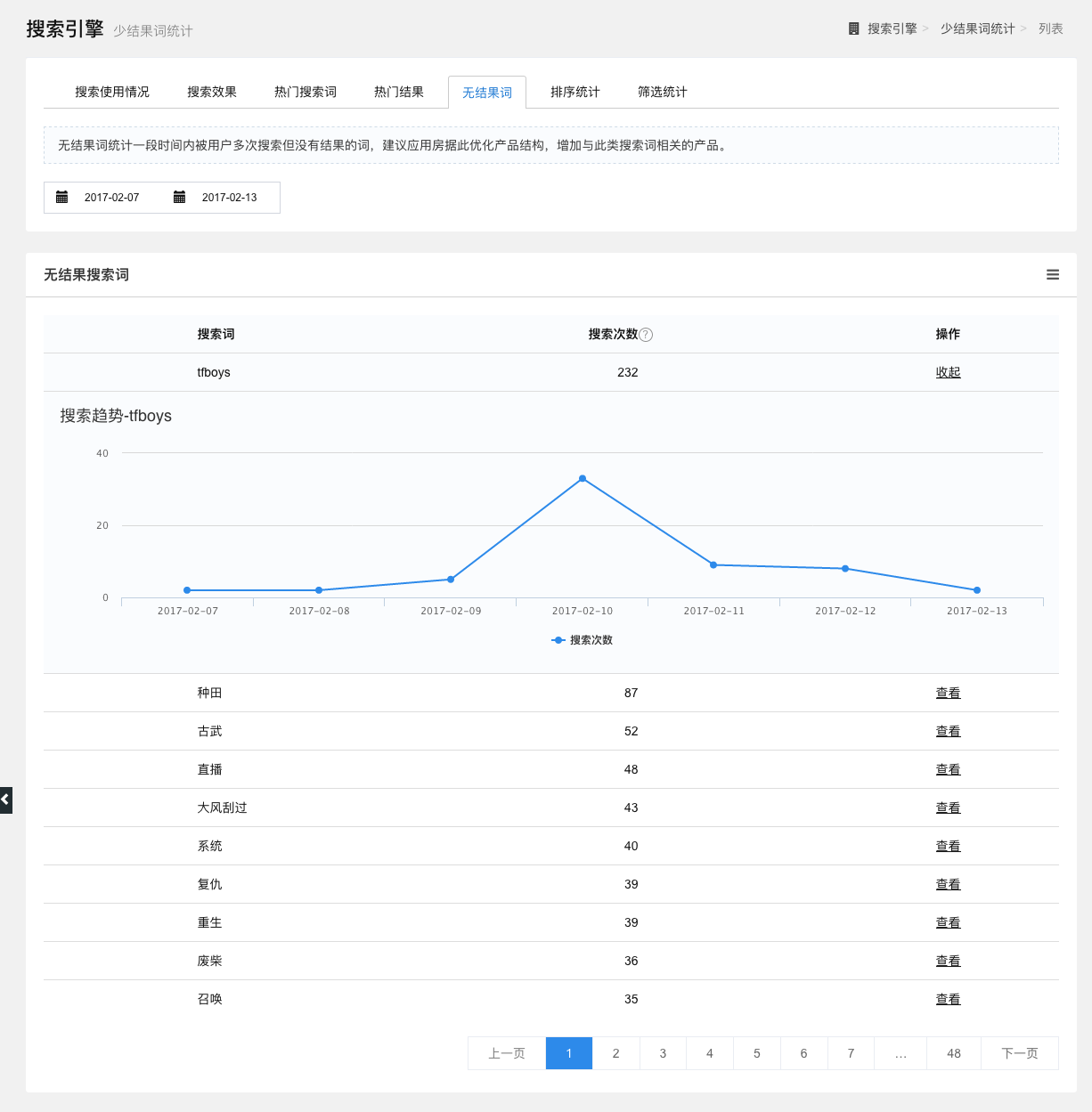
无结果词统计
统计一段时间内被用户多次搜索但没有结果的词。
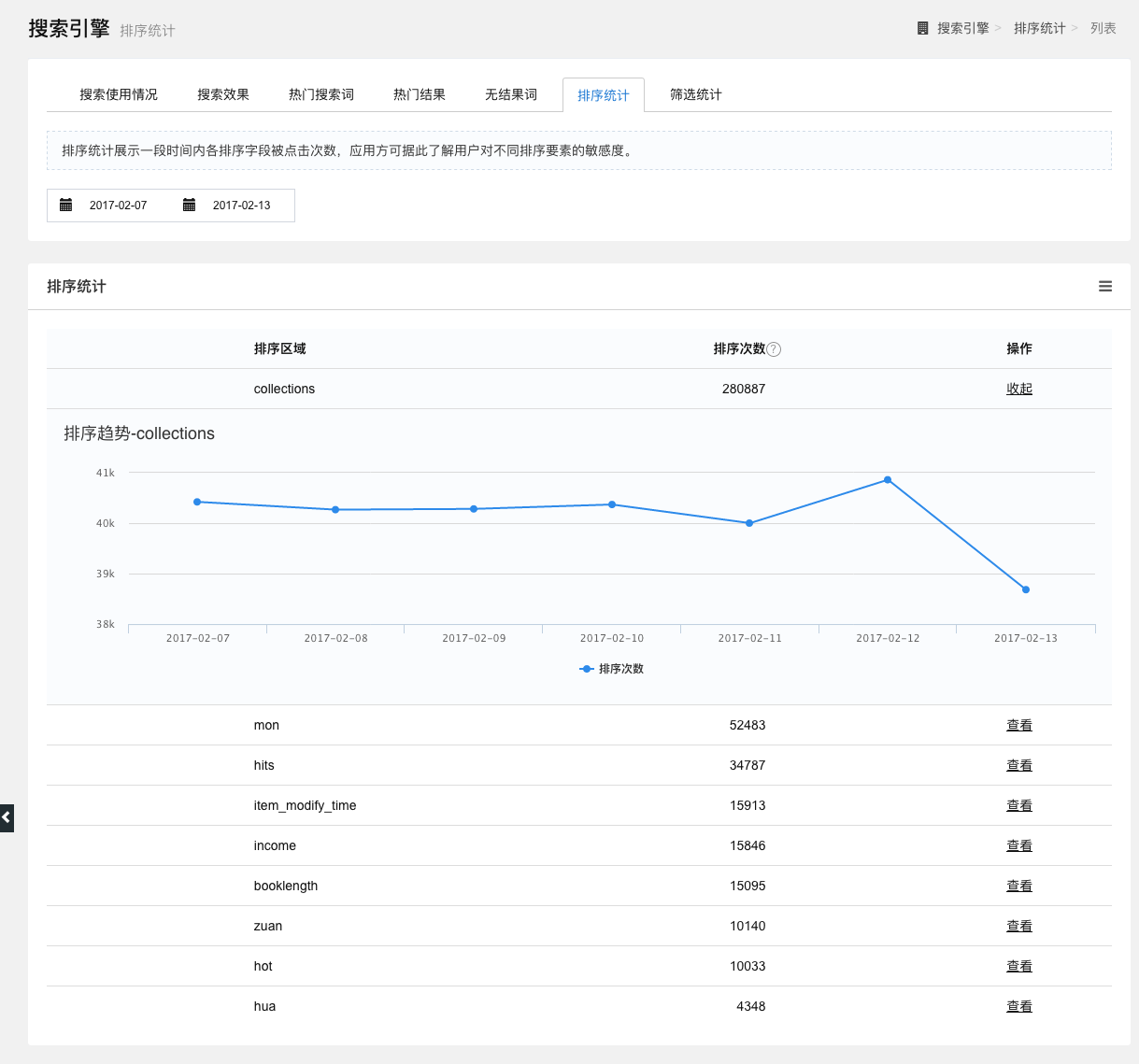
排序统计
统计一段时间内各排序字段被点击的次数。
筛选统计
统计一段时间内各筛选字段被点击的次数。
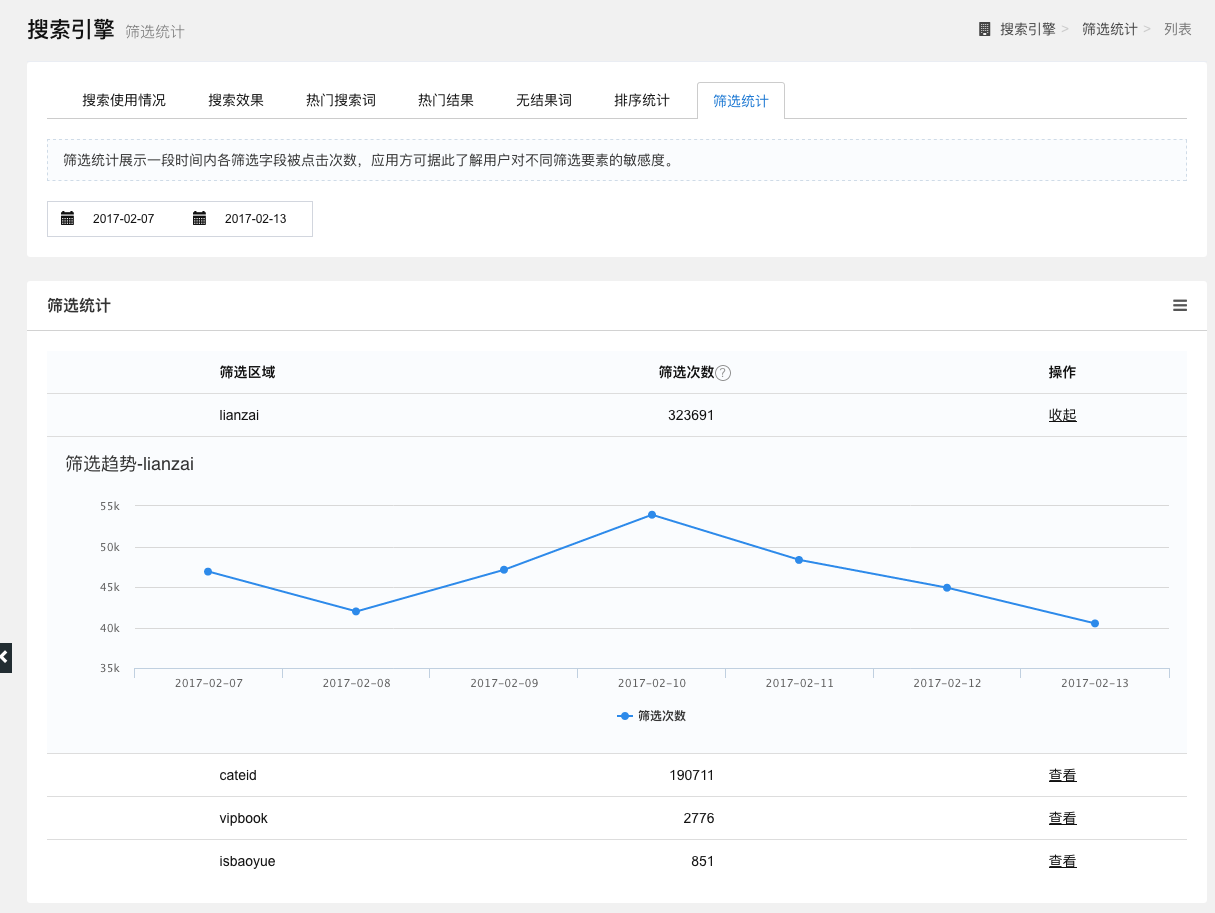
图5-7 筛选统计
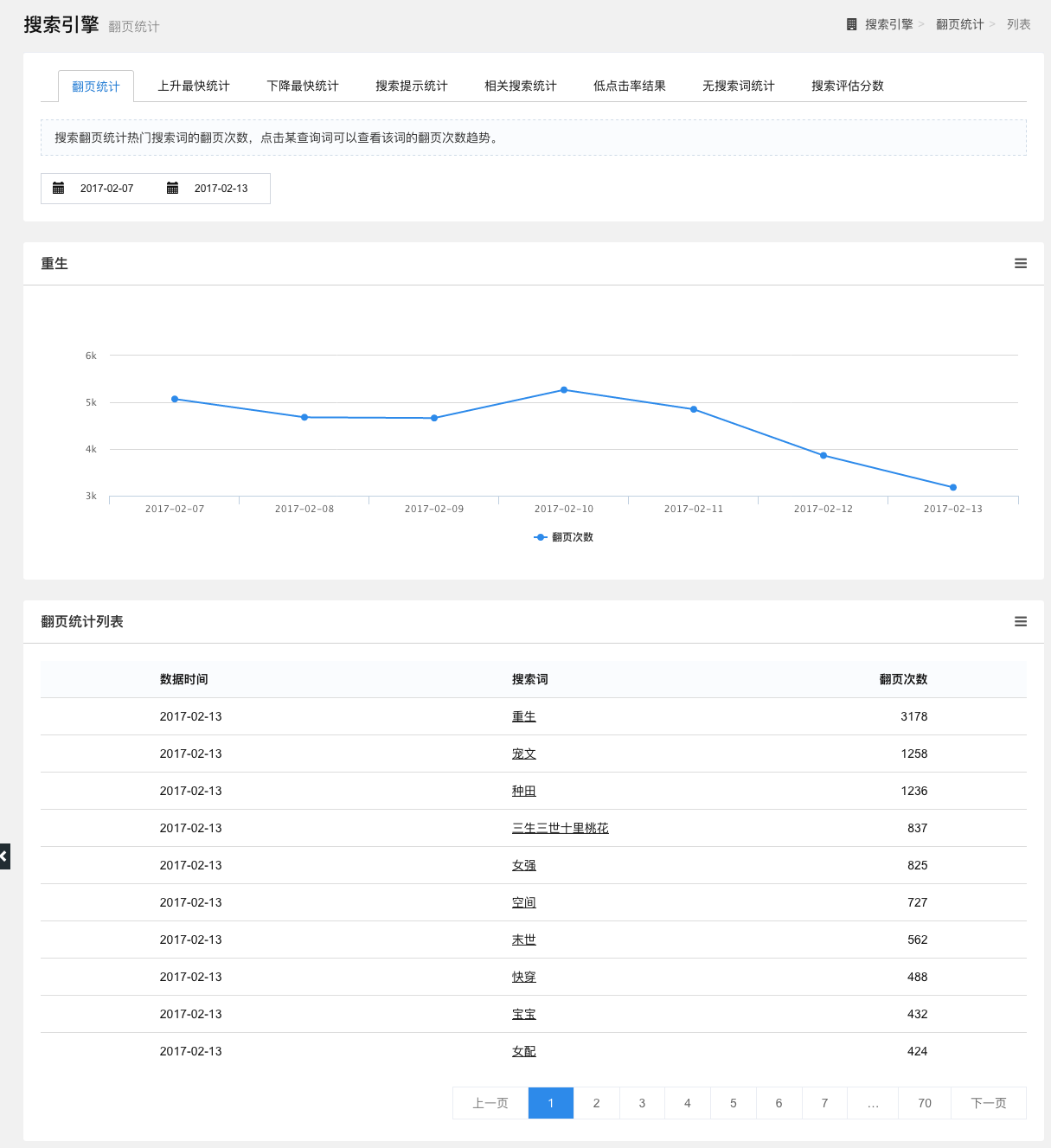
翻页统计
统计一段时间内热门搜索词的翻页次数,点击查询词可以查看该词的翻页次数趋势。
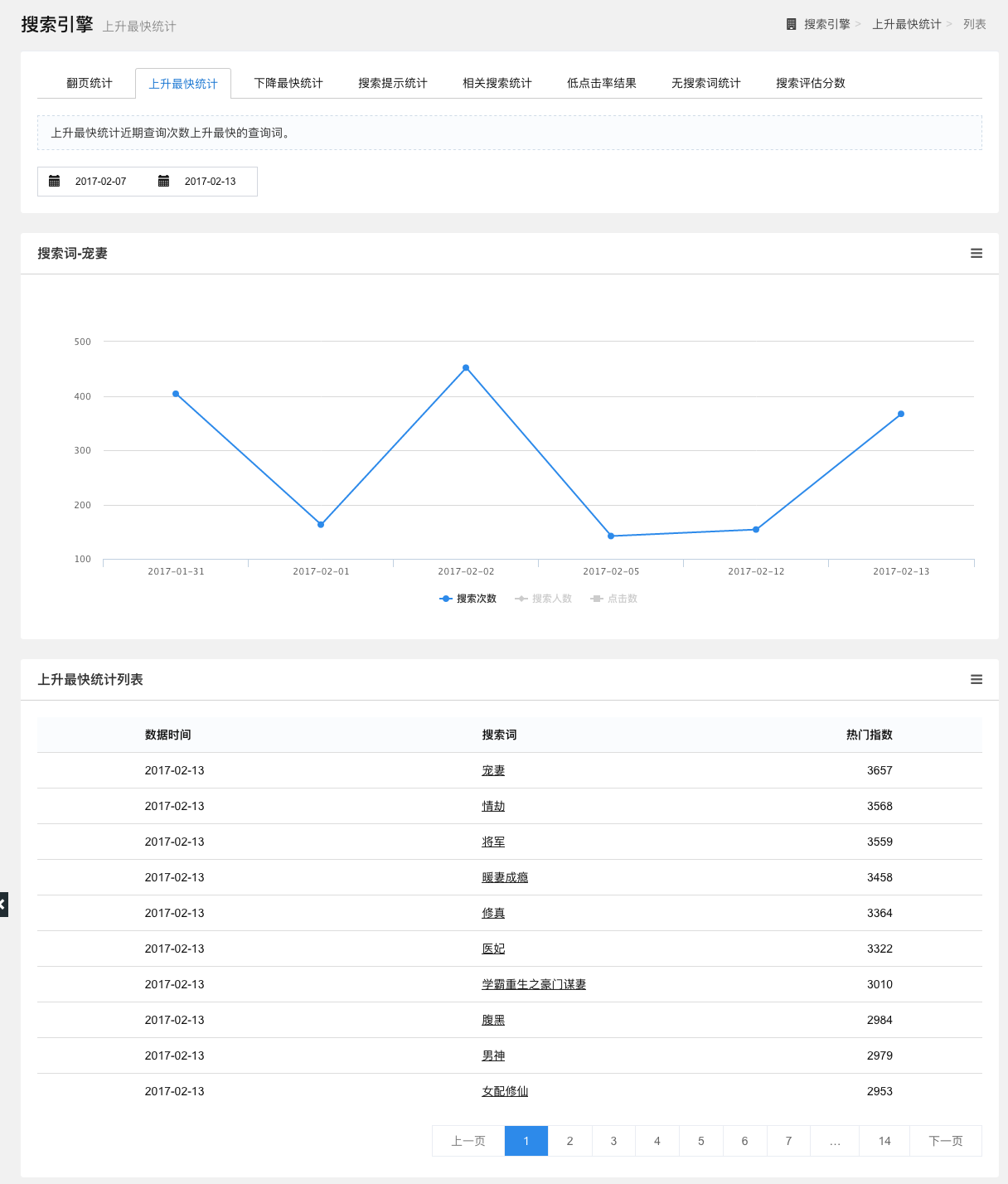
上升最快统计
统计一段时间内查询次数上升最快的查询词。
点击查询词可以查看该词的搜索次数、搜索人数和点击率,以折线图的形式展示,点击折线图下方的图例,可选择查看的数据。
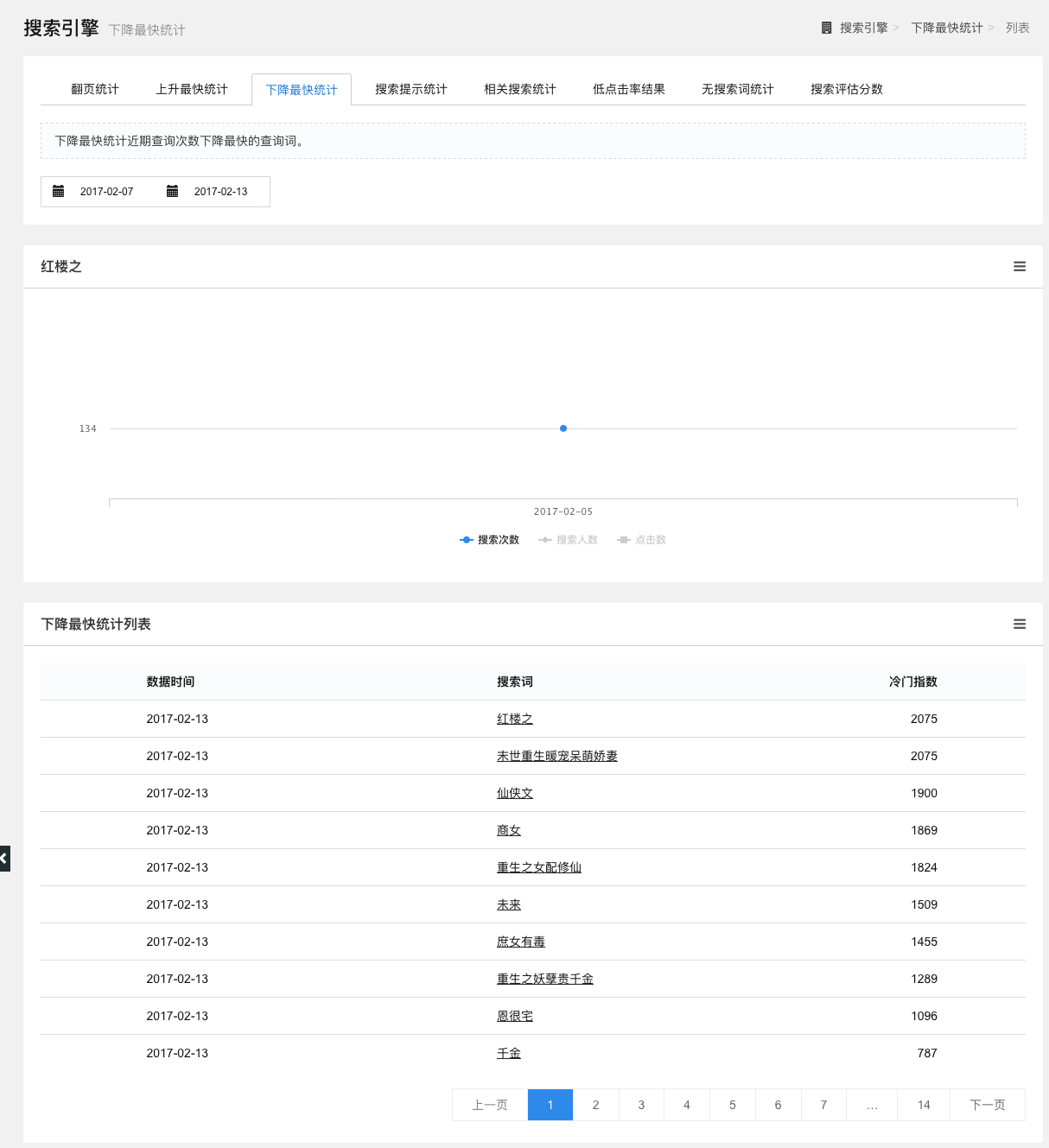
下降最快统计
统计一段时间内查询次数下降最快的查询词。
点击查询词可以查看该词的搜索次数、搜索人数和点击率,以折线图的形式展示,点击折线图下方的图例,可选择查看的数据。
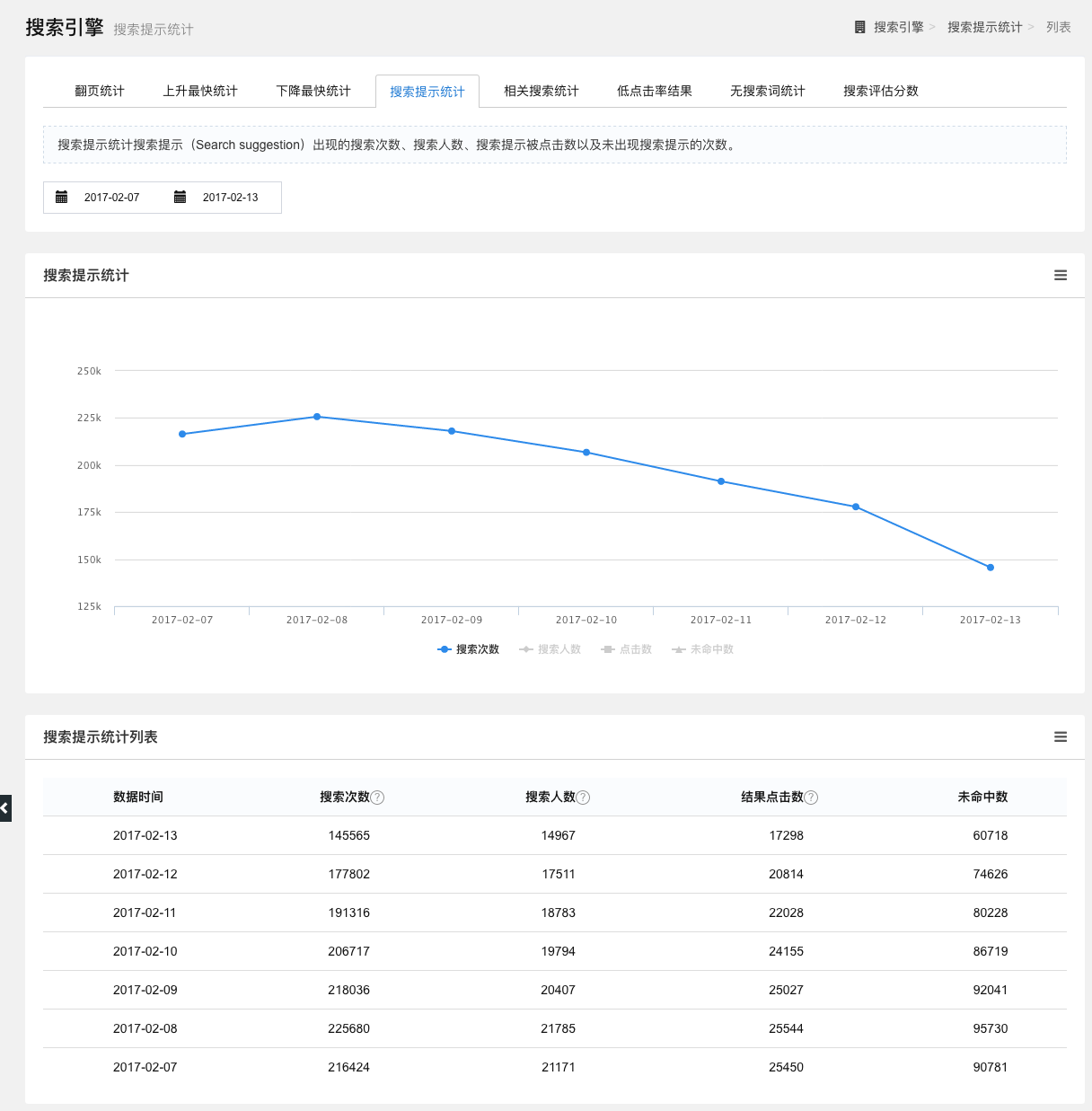
搜索提示统计
统计一段时间内搜索提示出现的搜索次数、搜索人数、搜索提示词被点击数和未出现搜索提示的次数。
点击查询词可以查看该词的搜索次数、搜索人数、点击数和未命中数,以折线图的形式展示,点击折线图下方的图例,可选择查看的数据。
相关搜索统计
统计一段时间内查询次数上升最快的查询词。
点击查询词可以查看该词的搜索次数、搜索人数和点击率,以折线图的形式展示,点击折线图下方的图例,可选择查看的数据。
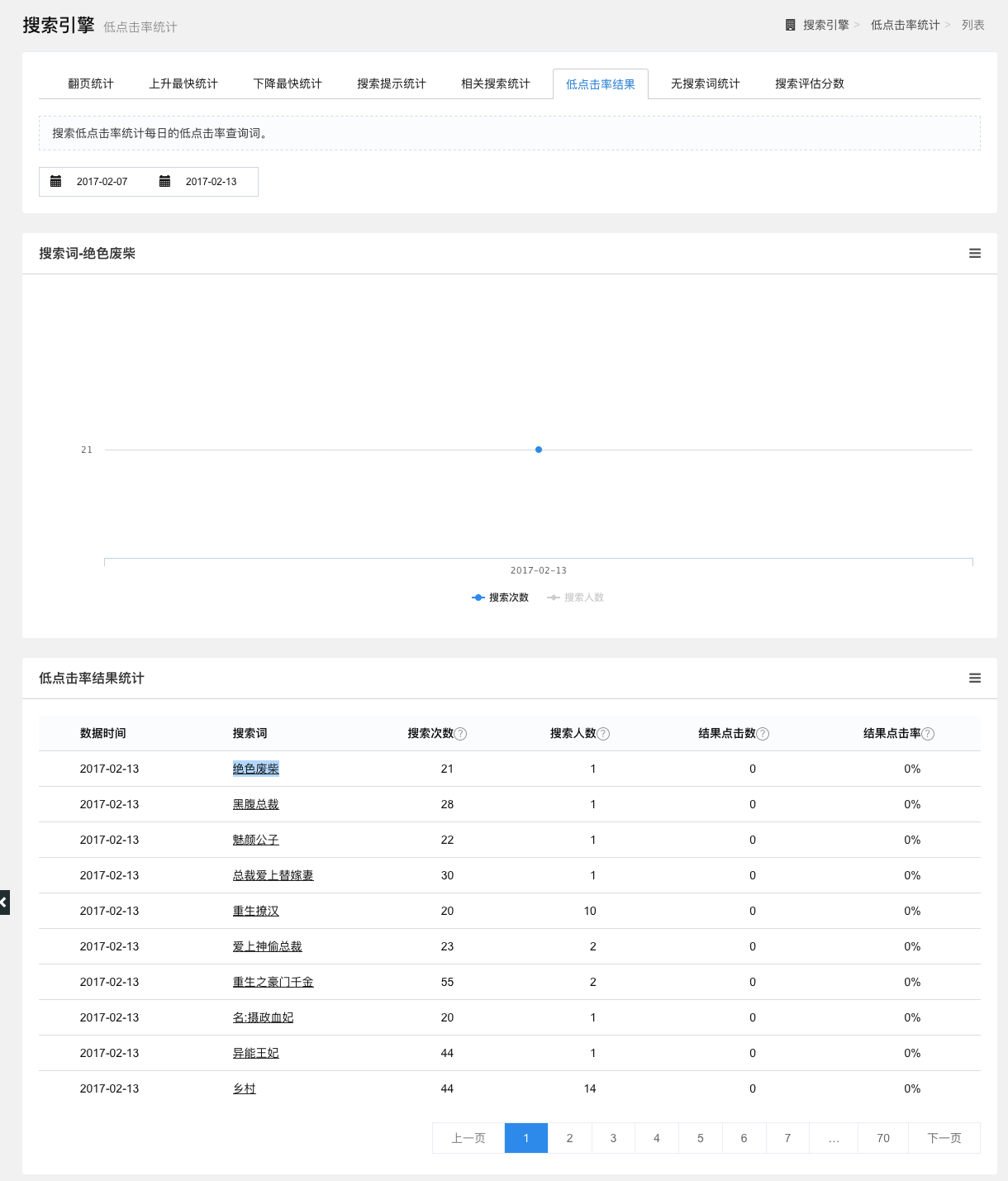
低点击率结果统计
统计低点击率的查询词,以列表形式展示数据时间、搜索词、搜索次数、搜索人数、结果点击数和结果点击率。
点击查询词可以查看该词的搜索次数和搜索人数,以折线图的形式展示,点击折线图下方的图例,可选择查看的数据。
无搜索词统计
统计一段时间内空搜索词的搜索人数、搜索结果点击数和无结果数。
以折线图和列表的形式展示,点击折线图下方的图例,可选择查看的数据。
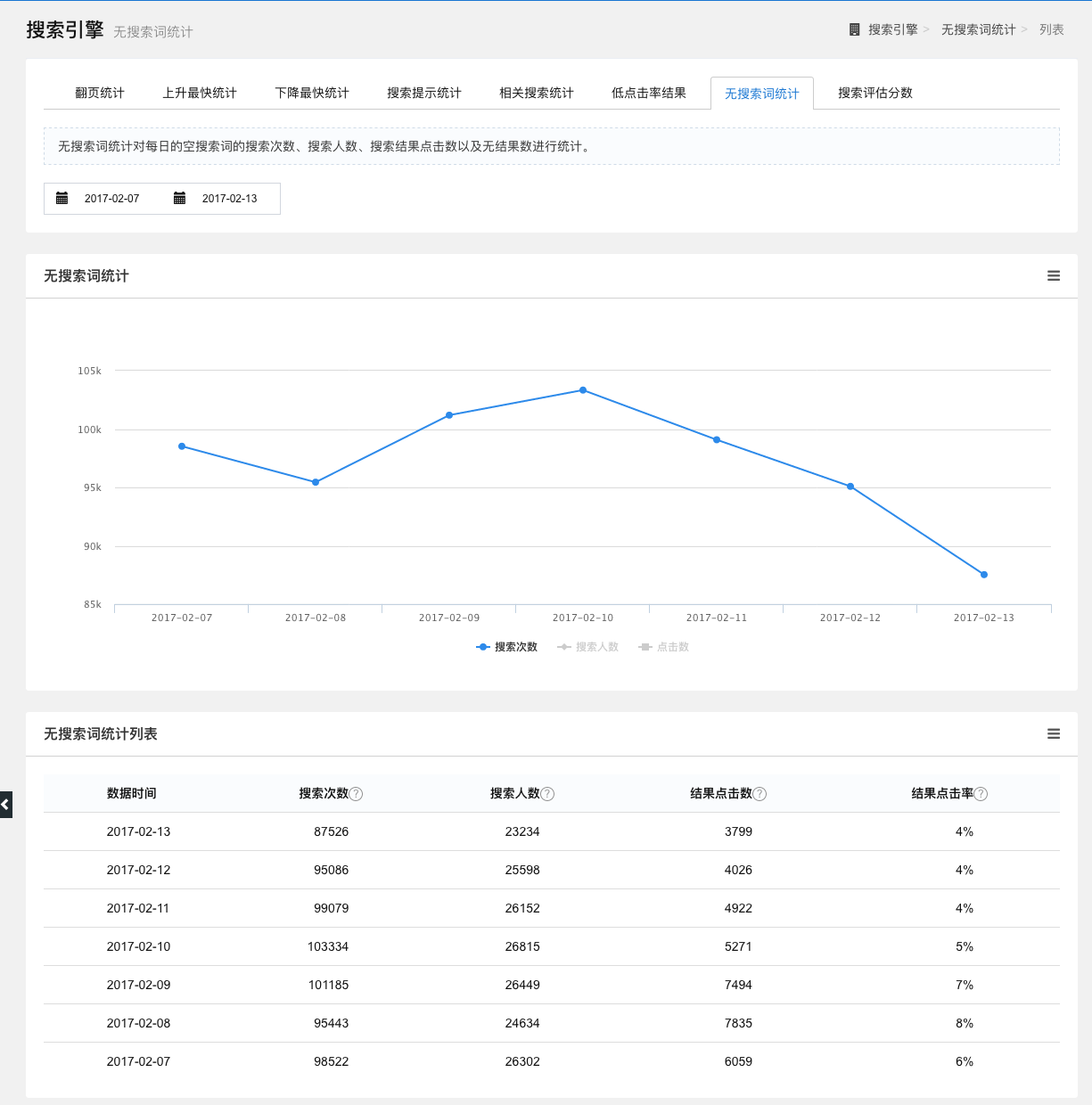
图5-14 无搜索词统计
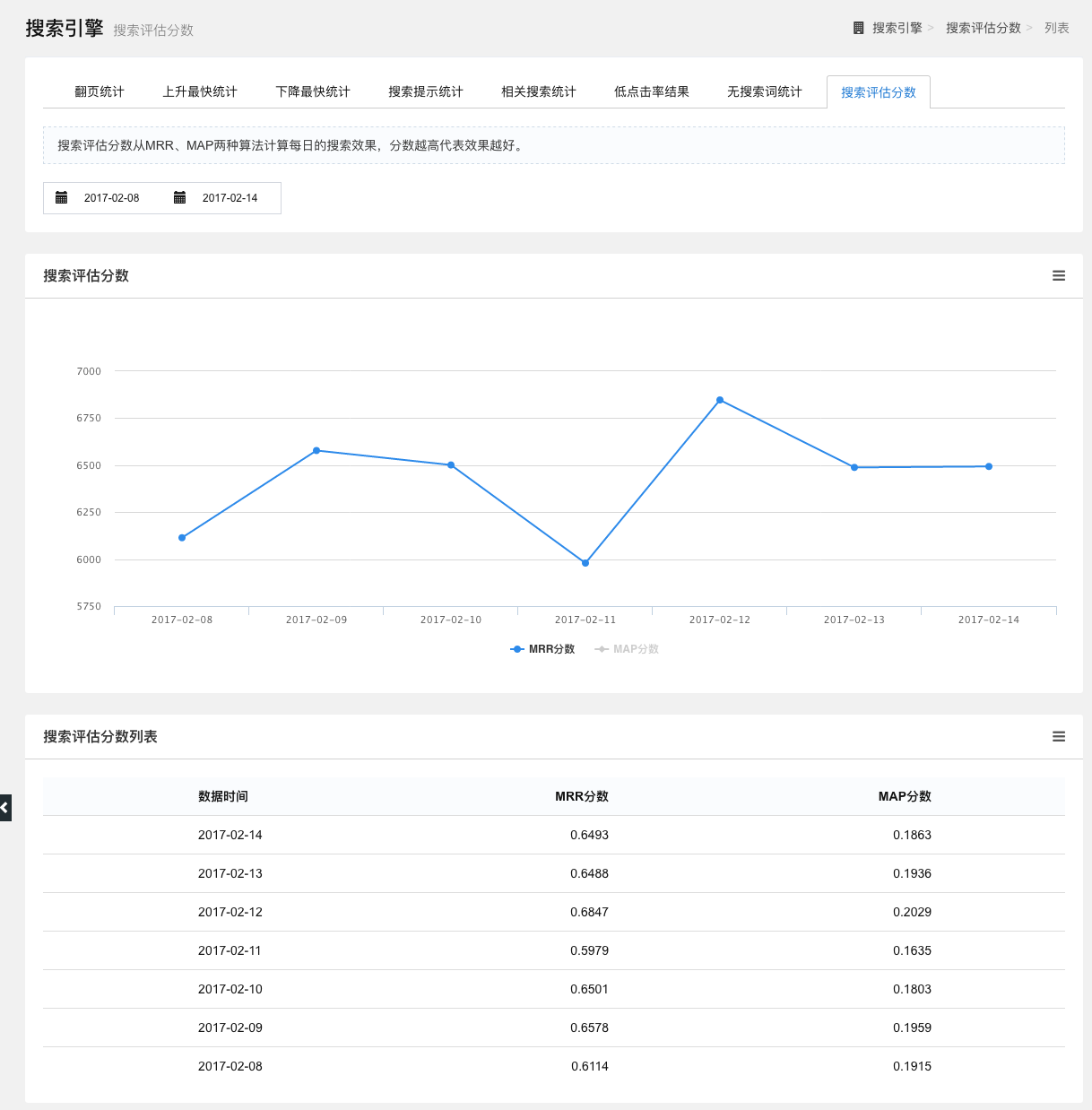
搜索评估分数统计
搜索评估分数从MRR和MAP两种算法计算每日的搜索效果。
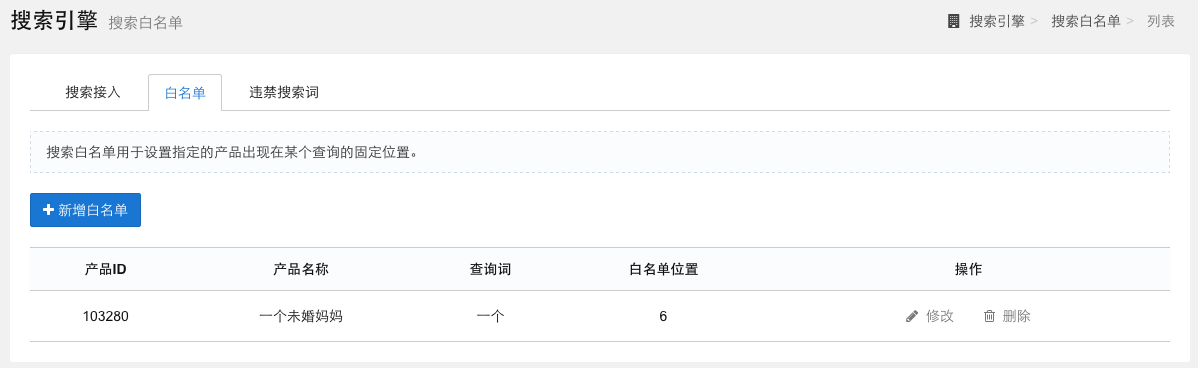
白名单
指定某产品出现在某查询结果的固定位置。如我们可通过设置搜索白名单,使用户在搜索关键词“A”时,指定产品“a”出现在搜索结果“第一位”。
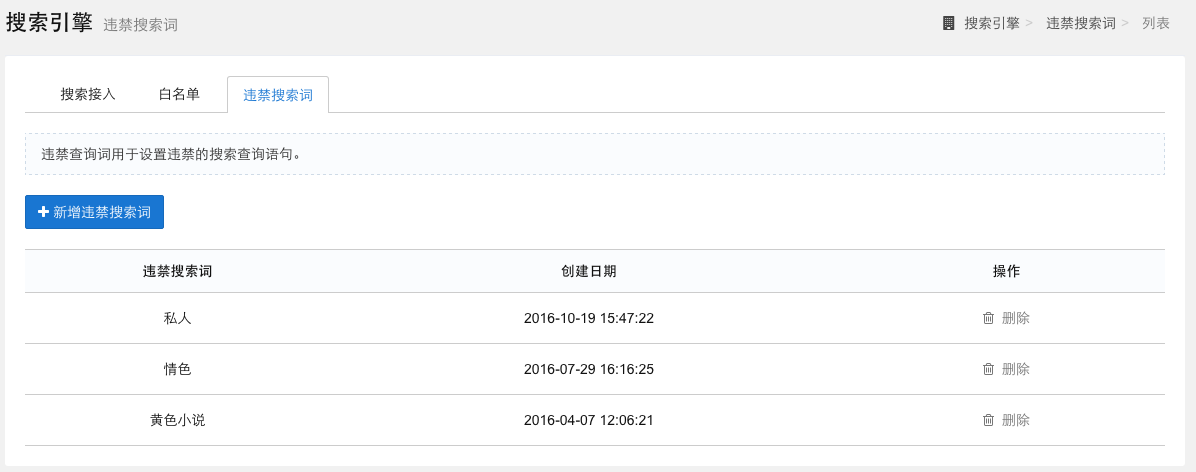
违禁搜索词
指定某违禁查询词不给出搜索结果。应用方可将一些违反相关法律规定的,诸如涉黄、涉政的敏感词设置为违禁查询词,当用户以这些词进行搜索时系统不给出任何搜索结果。
文本挖掘
文本挖掘模块为用户提供垃圾评论过滤、黄反文本审核和文本自动归类三大功能的数据统计。
垃圾评论
在垃圾评论模块用户可查看每日的垃圾评论检测情况并对检测结果不准确的案例进行标注反馈。
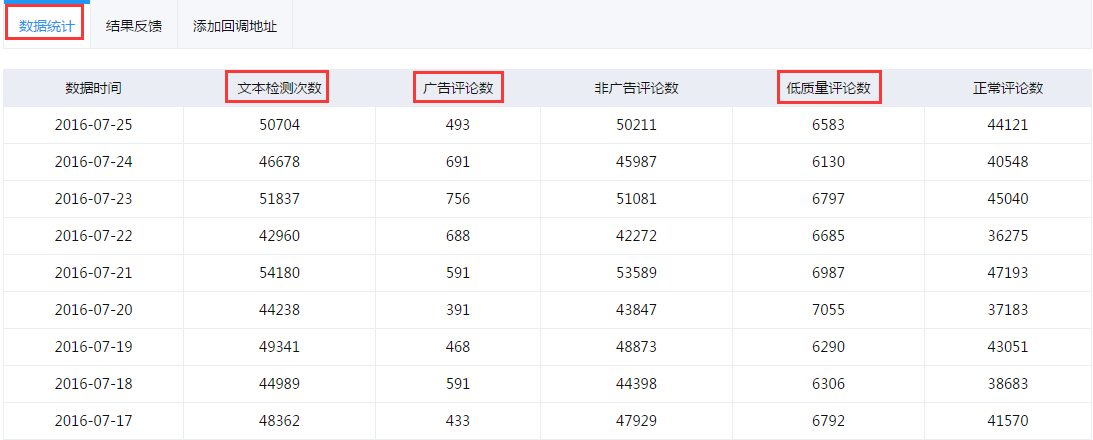
数据统计为用户展示每天检测的文本数、广告评论数和低质量文本数。
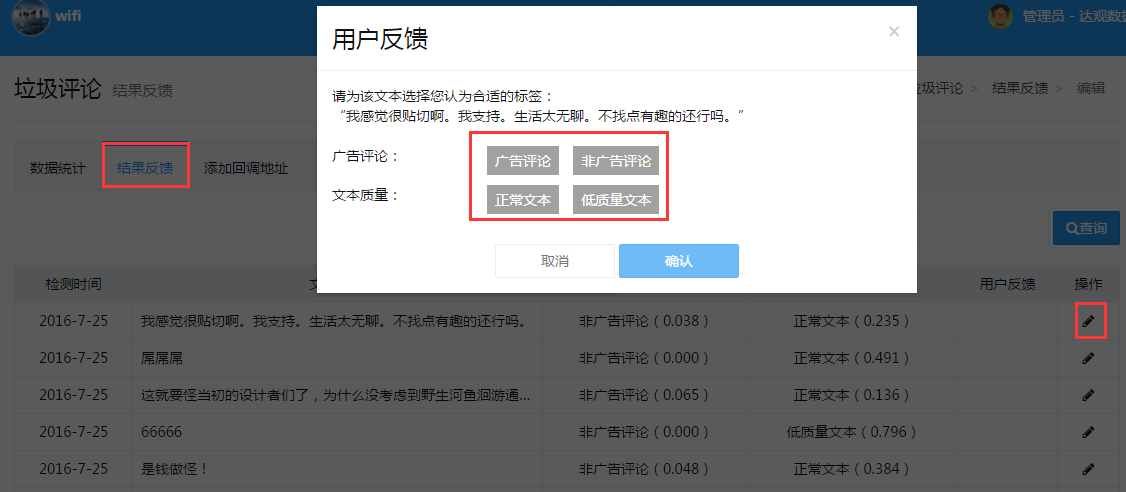
在结果反馈模块用户可看到所有检测的文本内容及检测结果,对存在偏差的检测结果进行标注反馈,达观会根据这些反馈及时对算法进行优化升级,提高精准度。如下图所示,用户可在点击操作标签后,重新确定此条评论是否为广告评论或低质量文本。
黄反审核
在黄反审核模块用户可以查看每日的文本审核情况并对审核结果不准确的案例进行标注反馈。
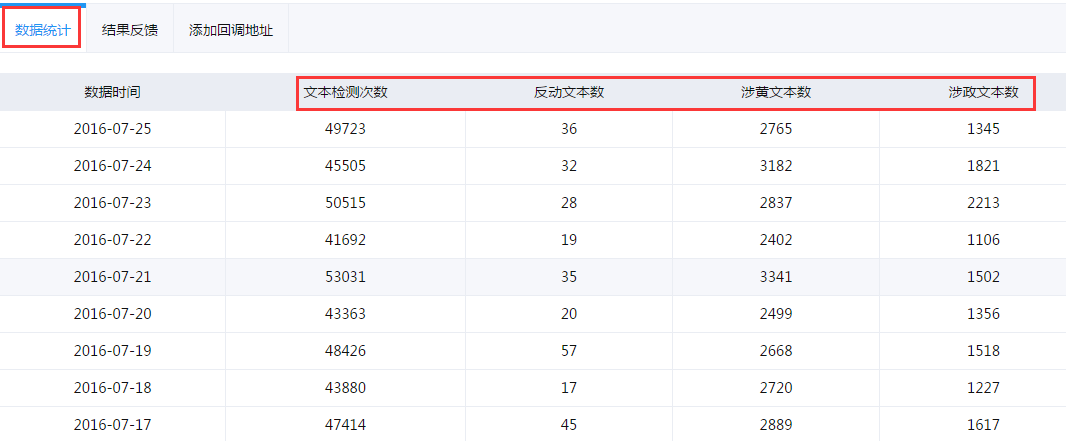
数据统计为用户展示每日文本的检测次数、识别出的反动文本数、涉黄文本数和涉政文本数。
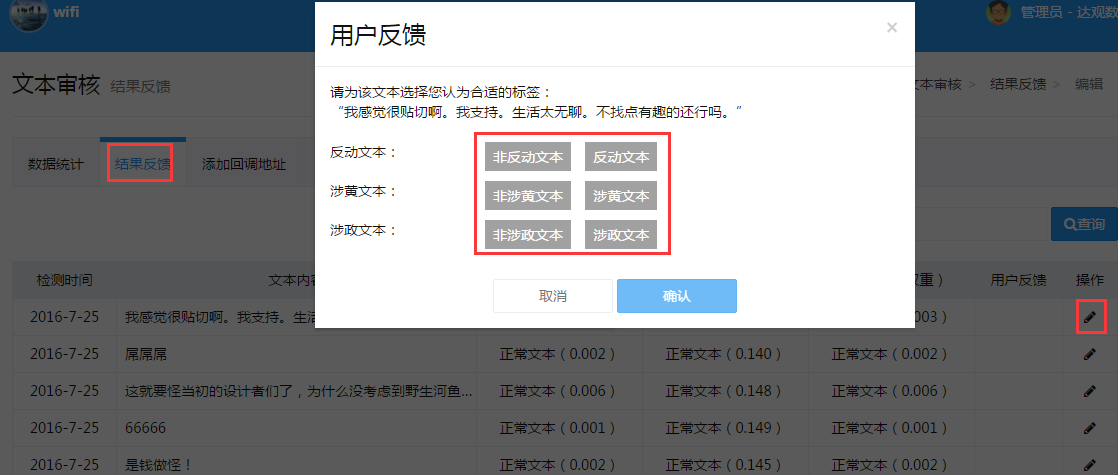
在结果反馈模块用户可以看到所有审核的文本内容及检测结果,对存在偏差的检测结果进行标注反馈,达观会根据这些反馈及时对算法进行优化升级,提高精准度。如下图所示,用户可以在点击操作标之后,重新确定此条文本是否为反动文本、涉黄文本或涉政文本。
文本归类
文本归类向用户展示总体检测次数及各类型文本数,并支持用户对检测结果不准确的案例进行标注反馈。
数据统计可让用户通过筛选快速看到各类别下的文本数。
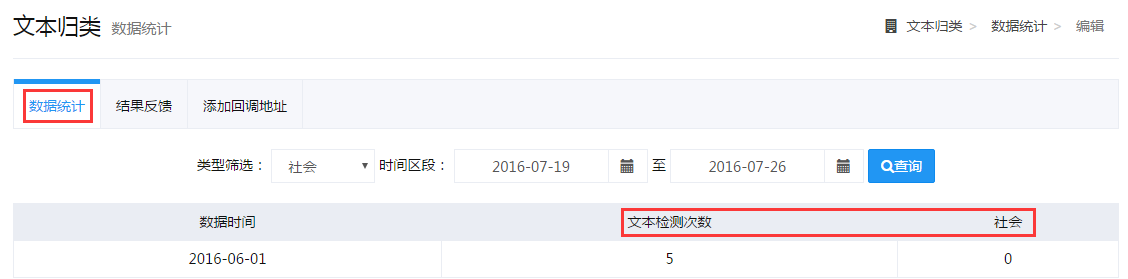
在结果反馈模块用户可看到所有文本的归类结果,并对存在偏差的检测结果进行标注反馈,达观会根据这些反馈及时对算法进行优化升级,提高精准度。

微信抓取
微信抓取为用户展示抓取的文章列表和相关数据统计并允许用户配置需要抓取的公众号。
抓取数据
抓取数据功能模块向用户展示所抓取的公众号及其文章的相关数据。
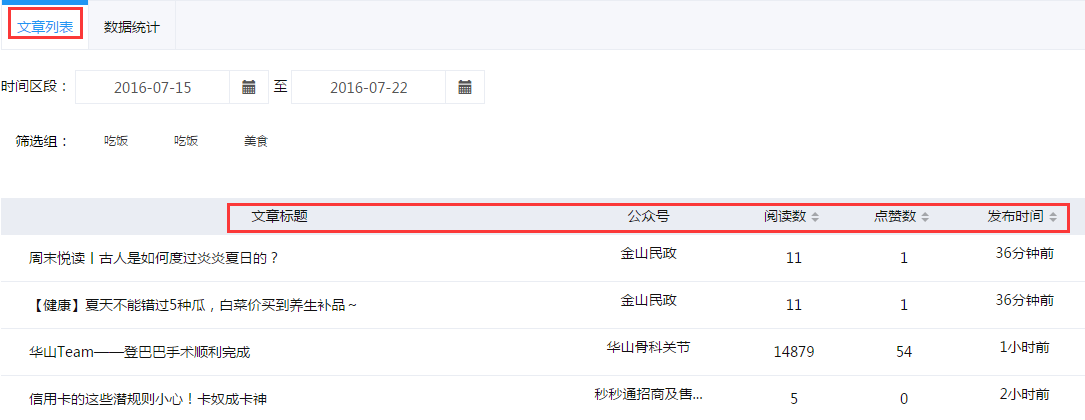
文章列表是用户已抓取的各公众号中的文章,列表中详细显示了所抓取文章的标题、公众号、阅读数、点赞数及发布时间。
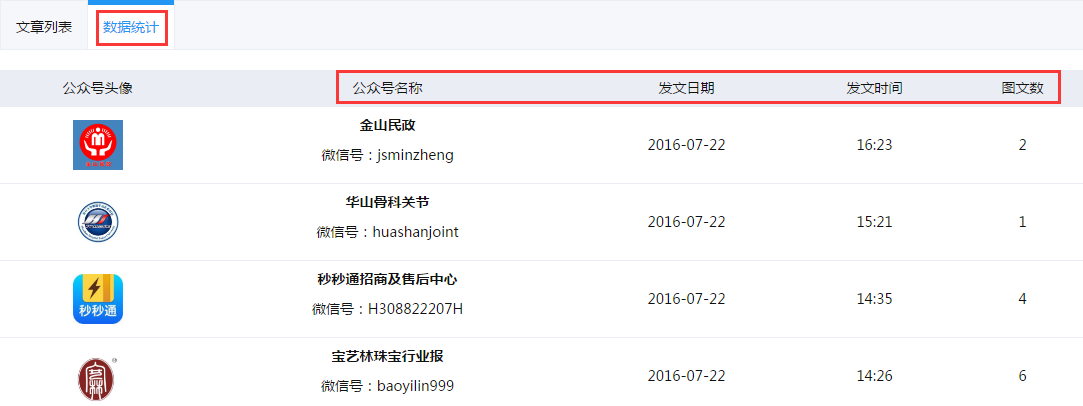
数据统计展示了用户所抓取的各公众号名称、发文日期、发文时间及发文数。
抓取配置
抓取配置功能模块可以让用户从公众号列表中抓取自己需要的公众号并为其添加标签,也可以通过添加文章筛选组来对已经抓取的公众号文章进行筛选。
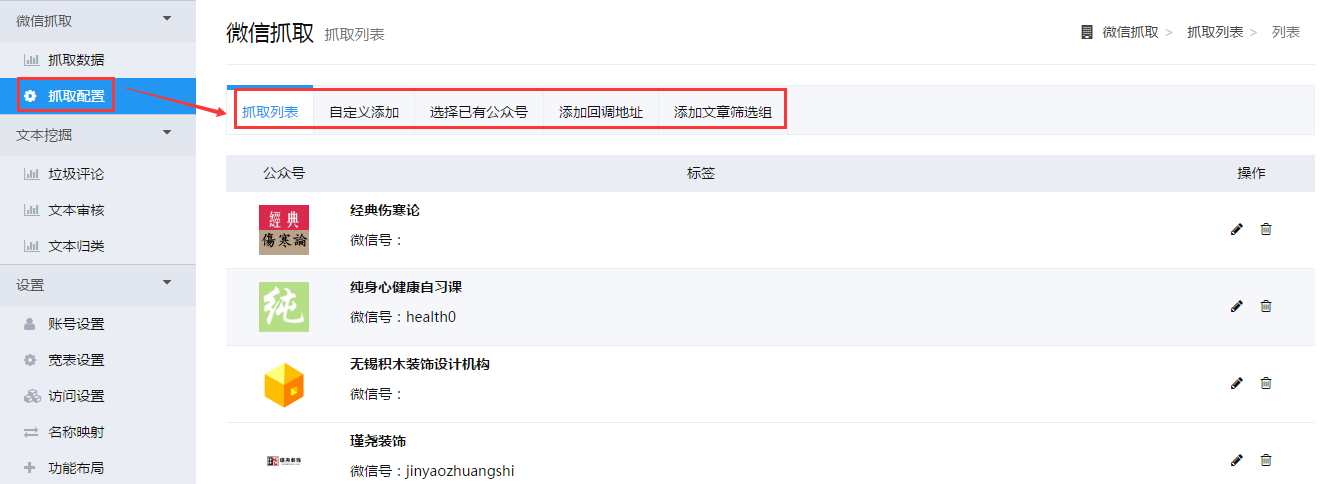
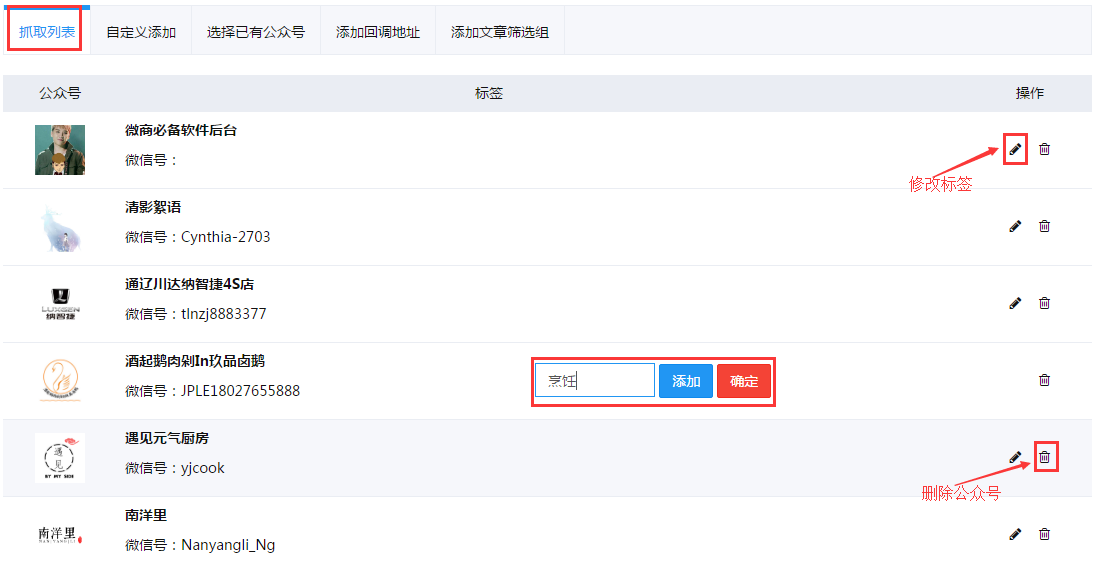
抓取列表
为用户展示正在抓取的公众号,支持其对各公众号进行标签修改或直接删除等操作 。
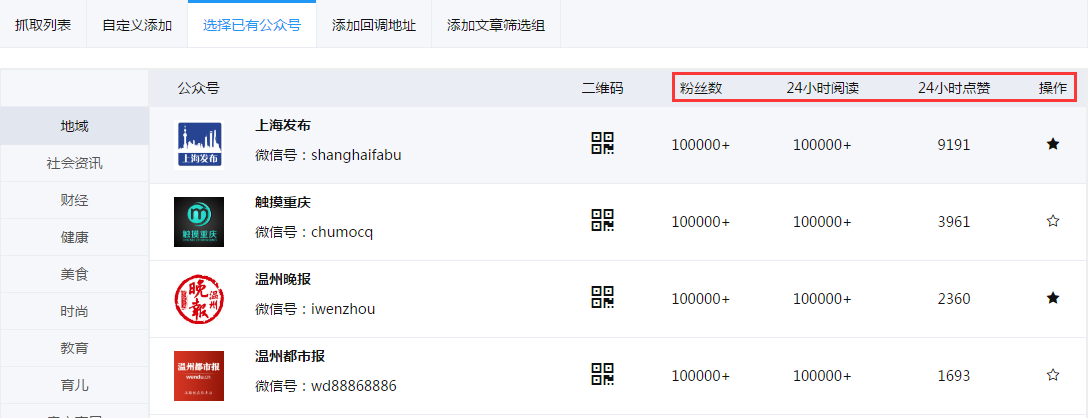
选择已有公众号向用户展示所有可抓取的微信公众号,用户可将意欲抓取的公众号添加到抓取列表。
欲了解更多,欢迎注册数据大师账户或直接联系我们客服人员。




